Análisis de Senderos
El análisis de senderos es una técnica estadística que permite descomponer correlaciones en diferentes componentes causales para entender las relaciones directas e indirectas entre diferentes variables. Esta técnica es especialmente útil cuando queremos entender el efecto de una variable sobre otra a través de una o más variables intermedias (o “mediadoras”).
En esta guía trabajaremos con el ejemplo de Análisis de Senderos presentado por la Dra. Monica Gereber en su taller de Análisis de Ecuaciones estructurales. En este se busca medir el efecto indirecto de la posición política en el nivel de acuerdo con castigos severos contra aquellos que cometen delitos, siendo la variables intermedia el autoritarismo de derechas. En modelo planteado puede verse en el siguiente esquema:

# Carga las bibliotecas necesarias
library(haven)
library(MVN)
library(lavaan)
## This is lavaan 0.6-15
## lavaan is FREE software! Please report any bugs.
library(semPlot)
library(semTable)
Las bibliotecas necesarias son haven para la importación de datos, MVN para la evaluación de la normalidad multivariante, lavaan para realizar análisis de senderos, semPlot para la visualización del modelo y semTable para la presentación de los resultados.
# Importar datos
datos <- read_sav(url("https://github.com/Clases-GabrielSotomayor/pruebapagina/raw/master/content/example/input/data/elsoc2016.sav"))
Los datos se importan de una URL utilizando la función read_sav de la biblioteca haven.
# Comprobación de supuestos
dim(datos)
## [1] 2984 12
cor(datos[,c("castigo_media","rwa_media","derecha", "izquierda" , "centro")],use = "complete.obs")
## castigo_media rwa_media derecha izquierda centro
## castigo_media 1.00000000 0.28343173 0.07611293 -0.09049472 -0.06169213
## rwa_media 0.28343173 1.00000000 0.11446537 -0.18306120 -0.02099511
## derecha 0.07611293 0.11446537 1.00000000 -0.14907230 -0.22929529
## izquierda -0.09049472 -0.18306120 -0.14907230 1.00000000 -0.27558230
## centro -0.06169213 -0.02099511 -0.22929529 -0.27558230 1.00000000
summary(datos)
## izquierda centro derecha indep_ning
## Min. :0.0000 Min. :0.0000 Min. :0.0000 Min. :0.0000
## 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:0.0000 1st Qu.:0.0000
## Median :0.0000 Median :0.0000 Median :0.0000 Median :0.0000
## Mean :0.1516 Mean :0.2971 Mean :0.1101 Mean :0.4412
## 3rd Qu.:0.0000 3rd Qu.:1.0000 3rd Qu.:0.0000 3rd Qu.:1.0000
## Max. :1.0000 Max. :1.0000 Max. :1.0000 Max. :1.0000
## NA's :69 NA's :69 NA's :69 NA's :69
## castigo1 castigo2 castigo_media rwa1 rwa2
## Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.0
## 1st Qu.:4.000 1st Qu.:4.000 1st Qu.:4.000 1st Qu.:3.000 1st Qu.:3.0
## Median :4.000 Median :4.000 Median :4.000 Median :4.000 Median :4.0
## Mean :4.199 Mean :4.155 Mean :4.177 Mean :3.578 Mean :3.7
## 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:4.000 3rd Qu.:4.0
## Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.000 Max. :5.0
## NA's :6 NA's :13 NA's :5 NA's :24 NA's :30
## rwa3 rwa4 rwa_media
## Min. :1.000 Min. :1.000 Min. :1.00
## 1st Qu.:3.000 1st Qu.:3.000 1st Qu.:3.25
## Median :4.000 Median :4.000 Median :4.00
## Mean :3.689 Mean :3.715 Mean :3.67
## 3rd Qu.:4.000 3rd Qu.:4.000 3rd Qu.:4.00
## Max. :5.000 Max. :5.000 Max. :5.00
## NA's :10 NA's :7 NA's :2
mvn(datos[,c("castigo_media","rwa_media","derecha", "izquierda" , "centro")],mvnTest = "mardia")
## $multivariateNormality
## Test Statistic p value Result
## 1 Mardia Skewness 6763.70732593015 0 NO
## 2 Mardia Kurtosis 15.37649877022 0 NO
## 3 MVN <NA> <NA> NO
##
## $univariateNormality
## Test Variable Statistic p value Normality
## 1 Anderson-Darling castigo_media 191.4103 <0.001 NO
## 2 Anderson-Darling rwa_media 85.0380 <0.001 NO
## 3 Anderson-Darling derecha 938.3859 <0.001 NO
## 4 Anderson-Darling izquierda 859.4875 <0.001 NO
## 5 Anderson-Darling centro 637.3425 <0.001 NO
##
## $Descriptives
## n Mean Std.Dev Median Min Max 25th 75th Skew
## castigo_media 2909 4.1801306 0.7738886 4 1 5 4.00 5 -1.3794682
## rwa_media 2909 3.6695600 0.7732055 4 1 5 3.25 4 -0.7948078
## derecha 2909 0.1103472 0.3133759 0 0 1 0.00 0 2.4859529
## izquierda 2909 0.1519422 0.3590266 0 0 1 0.00 0 1.9382301
## centro 2909 0.2976968 0.4573241 0 0 1 0.00 1 0.8844216
## Kurtosis
## castigo_media 3.0965422
## rwa_media 0.8365222
## derecha 4.1813994
## izquierda 1.7573405
## centro -1.2182168
Aquí se revisan varios supuestos antes de ajustar el modelo de senderos.
- dim(datos) muestra las dimensiones de los datos
- cor(datos,use = “complete.obs”) muestra las correlaciones entre variables
- summary(datos) ofrece un resumen estadístico de las variables
- mvn(datos) evalúa la normalidad multivariante, que es un supuesto clave en el análisis de senderos, en particular para es uso del método de estimación de máxima verosimilitud.
Especificación y estimación del modelo
Para especificar el modelo, debemos definir las variables que lo componen y sus relaciones. Para integrar esto en R, en el paquete lavaan, debemos expresar nuestro modelo de senderos en la sintaxis propia de dicho paquete:
| Sintaxis | Comando | Ejemplo |
|---|---|---|
| ~ | Regresar en | Regresar B sobre A: B ~ A |
| ~~ | (Co)varianza | Varianza de A: A ~~ A |
| =~ | Definir variable latente | Definir Definir Factor 1 por A-D: F1 =~ A + B + C + D |
| := | Definir parámetro fuera del modelo | Definir parámetro u2 como doble del cuadrado de u: u2 := 2*(u^2) |
| * | Etiquetar parámetros (etiqueta antes de símbolo) | Etiquetar la regresión de Z sobre X como b: Z ~ b*X |
# Especificar y ajustar el modelo de senderos
mod_sendero <- 'castigo_media ~ rwa_media
rwa_media ~ derecha + izquierda + centro'
ajus_sendero <- sem(mod_sendero, data=datos)
En este caso planteamos que el acuerdo con castigos violentos depende de el nivel de autoritarismo de derecha, mientras que este depende de la posición política, introducida como 3 variables dicotómicas.
La función sem() del paquete lavaan se utiliza para ajustar el modelo. En este modelo, ‘castigo_media’ se modela como una función de ‘rwa_media’, y ‘rwa_media’ se modela como una función de ‘derecha’, ‘izquierda’, y ‘centro’.
# Resumen de los resultados del modelo de senderos
summary(ajus_sendero, fit.measures = T, standardized = T, rsquare = T, modindices = T)
## lavaan 0.6.15 ended normally after 1 iteration
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 6
##
## Used Total
## Number of observations 2909 2984
##
## Model Test User Model:
##
## Test statistic 21.692
## Degrees of freedom 3
## P-value (Chi-square) 0.000
##
## Model Test Baseline Model:
##
## Test statistic 395.965
## Degrees of freedom 7
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.952
## Tucker-Lewis Index (TLI) 0.888
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -6573.366
## Loglikelihood unrestricted model (H1) -6562.520
##
## Akaike (AIC) 13158.733
## Bayesian (BIC) 13194.586
## Sample-size adjusted Bayesian (SABIC) 13175.522
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.046
## 90 Percent confidence interval - lower 0.029
## 90 Percent confidence interval - upper 0.065
## P-value H_0: RMSEA <= 0.050 0.591
## P-value H_0: RMSEA >= 0.080 0.001
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.021
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## castigo_media ~
## rwa_media 0.284 0.018 15.941 0.000 0.284 0.283
## rwa_media ~
## derecha 0.182 0.047 3.856 0.000 0.182 0.074
## izquierda -0.404 0.042 -9.679 0.000 -0.404 -0.187
## centro -0.094 0.033 -2.833 0.005 -0.094 -0.056
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .castigo_media 0.551 0.014 38.138 0.000 0.551 0.920
## .rwa_media 0.571 0.015 38.138 0.000 0.571 0.956
##
## R-Square:
## Estimate
## castigo_media 0.080
## rwa_media 0.044
##
## Modification Indices:
##
## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 1 castigo_media ~ derecha 6.112 0.109 0.109 0.044 0.141
## 2 castigo_media ~ izquierda 4.879 -0.086 -0.086 -0.040 -0.111
## 3 castigo_media ~ centro 9.832 -0.094 -0.094 -0.056 -0.122
## 4 rwa_media ~ castigo_media 13.858 -0.335 -0.335 -0.336 -0.336
## 5 derecha ~ castigo_media 1.209 0.008 0.008 0.020 0.020
## 6 izquierda ~ castigo_media 8.243 -0.024 -0.024 -0.053 -0.053
## 7 centro ~ castigo_media 11.668 -0.036 -0.036 -0.061 -0.061
La función summary() proporciona un resumen de los resultados, incluyendo varias medidas de ajuste, coeficientes estandarizados, los coeficientes de determinación (R^2) y los índices de modificación.
En primer lugar debemos ver si el ajuste global del modelo es apropiado.
Test de chi cuadrado: Este es un test que compara el modelo estimado con el modelo de saturación (uno que ajusta perfectamente los datos). Un resultado no significativo (p>0.05) sugiere que el modelo de la hipótesis se ajusta igual de bien que el modelo saturado. En este caso, el p-valor es 0.000, lo que indica que el modelo no se ajusta perfectamente a los datos.
CFI/TLI: Estos son índices de ajuste comparativo que comparan el ajuste del modelo de la hipótesis con el de un modelo nulo. Valores por encima de 0.90 suelen considerarse aceptables, y por encima de 0.95 muy buenos. En este caso, el CFI es 0.952 y el TLI es 0.888, lo que sugiere que el modelo se ajusta razonablemente bien a los datos, aunque podría ser mejor.
RMSEA: Es una medida de ajuste absoluto que indica el error de aproximación en el ajuste del modelo. Valores por debajo de 0.05 se consideran buenos, y por debajo de 0.08 aceptables. Aquí, el RMSEA es 0.046, lo que indica un buen ajuste.
SRMR: Es la media cuadrática de los residuos estandarizados, una medida del ajuste promedio del modelo. Valores por debajo de 0.08 se consideran buenos. En este caso, el SRMR es 0.021, lo que indica un muy buen ajuste.
Luego revisamos los coeficientes path en el modelo. Cada coeficiente indica la magnitud y dirección del efecto de una variable sobre otra. En este caso, vemos que “autoritarismo de derechas” tiene un efecto positivo significativo en “castigo severo” (coeficiente = 0.284, p < 0.001), ser de “derecha” (respecto a ser independiente) tiene un efecto positivo significativo en “autoritarismo de derechas” (coeficiente = 0.182, p < 0.001), ser de “izquierda” (respecto a ser independiente) tiene un efecto negativo significativo en “autoritarismo de derechas” (coeficiente = -0.404, p < 0.001), y ser de “centro” (respecto a ser independiente) tiene un efecto negativo significativo en “autoritarismo de derechas” (coeficiente = -0.094, p = 0.005).
El R-cuadrado para cada una de las variables dependientes (“castigo severo” y “autoritarismo de derechas”) proporciona la cantidad de varianza explicada por las variables independientes en el modelo. En este caso, el 8% de la varianza en “castigo severo” se explica por “autoritarismo de derechas”, y el 4.4% de la varianza en “autoritarismo de derechas” se explica por “derecha”, “izquierda” y “centro”.
# Crear una tabla de resultados en formato APA
semTable(ajus_sendero, type = "html", paramSets = c("loadings", "slopes", "latentcovariances",
"fits", "constructed"), file = "resultados_sendero")
| Model | ||||
| Estimate | Std. Err. | z | p | |
| Regression Slopes | ||||
| castigo_media | ||||
| rwa.media | 0.28 | 0.02 | 15.94 | .000 |
| rwa_media | ||||
| derecha | 0.18 | 0.05 | 3.86 | .000 |
| izquierda | -0.40 | 0.04 | -9.68 | .000 |
| centro | -0.09 | 0.03 | -2.83 | .005 |
| Fit Indices | ||||
| χ2 | 21.69(3) | .000 | ||
| CFI | 0.95 | |||
| TLI | 0.89 | |||
| RMSEA | 0.05 | |||
| +Fixed parameter | ||||
Aquí usamos semTable() para generar una tabla con los resultados principales del modelo.
# Mostrar la tabla de resultados en un navegador
browseURL("resultados_sendero.html")
Aquí utilizamos browseURL() para abrir el archivo HTML generado en el navegador por defecto. Es una manera eficaz de visualizar la tabla de resultados.
# Especificar y ajustar el modelo de senderos con efectos indirectos
mod_sendero3 <- 'castigo_media ~ a* rwa_media + c*derecha
rwa_media ~ b* derecha + izquierda + centro
ind_derecha_rwa := a*b
total_derecha_rwa := (a*b)+c'
ajus_sendero3 <- sem(mod_sendero3, data=datos)
Este bloque de código define y ajusta un modelo de senderos que incluye la definición de efectos indirectos, para que R nos entregue su significación. Además se agregar un efecto directo de ser de derecha sobre el nivel de apoyo a los castigos severos contra aquellos que cometen delitos, considerando las recomendaciones del. Aquí se está modelando ‘castigo_media’ como una función de ‘rwa_media’ y ‘derecha’, y ‘rwa_media’ como una función de ‘derecha’, ‘izquierda’, y ‘centro’. Además, se introducen dos parámetros nuevos, ‘ind_derecha_rwa’ y ‘total_derecha_rwa’, que representan los efectos indirectos y totales de ‘derecha’ sobre ‘castigo_media’ a través de ‘rwa_media’, respectivamente.

# Resumen de los resultados del modelo de senderos con efectos indirectos
summary(ajus_sendero3, fit.measures = T, standardized = T, rsquare = T, modindices = T)
## lavaan 0.6.15 ended normally after 2 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 7
##
## Used Total
## Number of observations 2909 2984
##
## Model Test User Model:
##
## Test statistic 15.573
## Degrees of freedom 2
## P-value (Chi-square) 0.000
##
## Model Test Baseline Model:
##
## Test statistic 395.965
## Degrees of freedom 7
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.965
## Tucker-Lewis Index (TLI) 0.878
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -6570.307
## Loglikelihood unrestricted model (H1) -6562.520
##
## Akaike (AIC) 13154.614
## Bayesian (BIC) 13196.443
## Sample-size adjusted Bayesian (SABIC) 13174.201
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.048
## 90 Percent confidence interval - lower 0.028
## 90 Percent confidence interval - upper 0.072
## P-value H_0: RMSEA <= 0.050 0.499
## P-value H_0: RMSEA >= 0.080 0.012
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.015
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## castigo_media ~
## rwa_media (a) 0.279 0.018 15.569 0.000 0.279 0.278
## derecha (c) 0.109 0.044 2.475 0.013 0.109 0.044
## rwa_media ~
## derecha (b) 0.182 0.047 3.856 0.000 0.182 0.074
## izquierda -0.404 0.042 -9.679 0.000 -0.404 -0.187
## centro -0.094 0.033 -2.833 0.005 -0.094 -0.056
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .castigo_media 0.549 0.014 38.138 0.000 0.549 0.918
## .rwa_media 0.571 0.015 38.138 0.000 0.571 0.956
##
## R-Square:
## Estimate
## castigo_media 0.082
## rwa_media 0.044
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## ind_derecha_rw 0.051 0.014 3.743 0.000 0.051 0.021
## total_derch_rw 0.160 0.046 3.491 0.000 0.160 0.065
##
## Modification Indices:
##
## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 1 derecha ~~ derecha 0.000 0.000 0.000 0.000 0.000
## 2 derecha ~~ izquierda 0.000 0.000 0.000 NA 0.000
## 3 derecha ~~ centro 0.000 0.000 0.000 NA 0.000
## 4 castigo_media ~ izquierda 3.621 -0.075 -0.075 -0.035 -0.097
## 5 castigo_media ~ centro 6.988 -0.082 -0.082 -0.048 -0.105
## 6 rwa_media ~ castigo_media 8.075 -0.304 -0.304 -0.304 -0.304
## 7 derecha ~ castigo_media 15.538 -0.093 -0.093 -0.229 -0.229
## 8 derecha ~ rwa_media 0.000 0.000 0.000 0.000 0.000
## 9 derecha ~ izquierda 0.000 0.000 0.000 0.000 0.000
## 10 derecha ~ centro 0.000 0.000 0.000 0.000 0.000
## 11 izquierda ~ castigo_media 8.494 -0.025 -0.025 -0.053 -0.053
## 12 izquierda ~ rwa_media 0.000 0.000 0.000 0.000 0.000
## 13 izquierda ~ derecha 0.000 0.000 0.000 0.000 0.000
## 14 izquierda ~ centro 0.000 0.000 0.000 0.000 0.000
## 15 centro ~ castigo_media 11.707 -0.036 -0.036 -0.061 -0.061
## 16 centro ~ rwa_media 0.000 0.000 0.000 0.000 0.000
## 17 centro ~ derecha 0.000 0.000 0.000 0.000 0.000
## 18 centro ~ izquierda 0.000 0.000 0.000 0.000 0.000
Por último, se utiliza summary() para proporcionar un resumen de los resultados del modelo que incluye los efectos indirectos. Esto incluirá las mismas estadísticas que antes, pero ahora también incluirá los efectos indirectos y totales que hemos especificado.
ind_derecha_rwa: El efecto indirecto de “derecha” en “castigo severo” a través de “autoritarismo de derechas” es significativo y positivo (Estimate = 0.051, p < 0.000). Esto significa que, manteniendo todo lo demás constante, ser de derecha (respecto de ser independiente) incrementa la puntuación en “castigo severo” a través de su efecto en “autoritarismo de derechas”.
total_derecha_rwa: El efecto total de “derecha” en “castigo severo” es también significativo y positivo (Estimate = 0.160, p < 0.000). Esto significa que, manteniendo todo lo demás constante, ser de derecha (respecto de ser independiente) incrementa la puntuación en “castigo severo” tanto directamente como indirectamente a través de su efecto en “autoritarismo de derechas”.
# Diagrama del modelo de senderos
semPaths(ajus_sendero3, # modelo ajustado
what = "std", # mostrar cargas estandarizadas
label.cex = 1, edge.label.cex = 1, # tamaño de las etiquetas y caracteres
residuals = FALSE, # no mostrar residuos
edge.color = "black") # color de las flechas
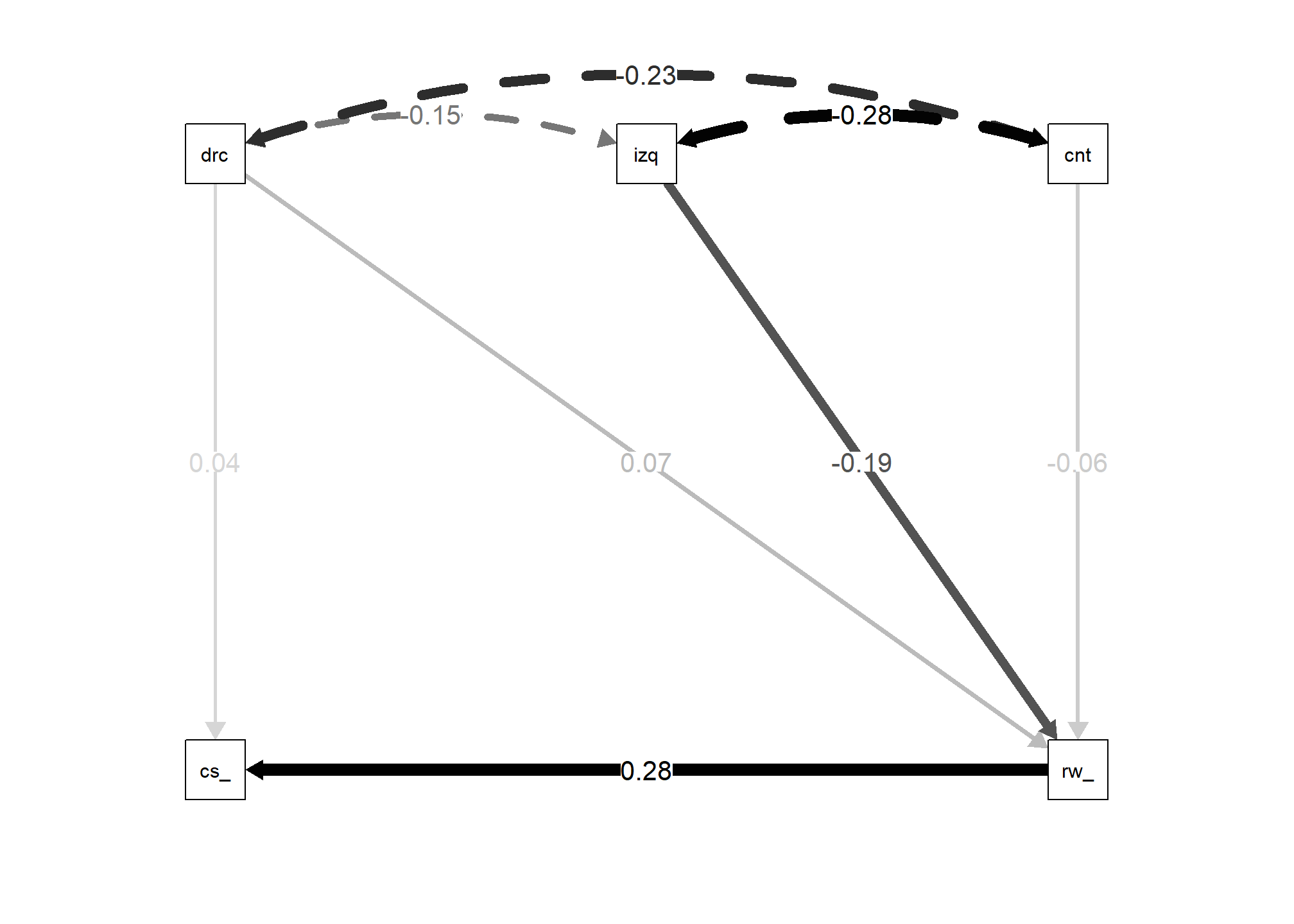
Aquí usamos semPaths() para generar un diagrama del modelo de senderos que hemos ajustado. Los argumentos de esta función son similares a los que hemos usado antes. ajus_sendero3 es el modelo ajustado, what = “std” indica que se deben mostrar las cargas estandarizadas en lugar de las no estandarizadas, label.cex = 1 y edge.label.cex = 1 controlan el tamaño de las etiquetas y de las flechas respectivamente, residuals = FALSE indica que no se deben mostrar los residuos en el diagrama, y edge.color = “black” establece el color de las flechas a negro.
Este diagrama proporciona una representación visual del modelo de senderos que hemos ajustado, lo que puede facilitar su interpretación. En el diagrama, las variables observables se representan como rectángulos, las variables latentes (si las hay) como óvalos, y las relaciones entre variables como flechas. Las cargas factoriales o coeficientes de las rutas se representan junto a las flechas correspondientes.