Análisis de regresión logística
0. Objetivo del práctico
El objetivo de este práctico es aprender a ejecutar análisis de regresión logística binaria en R, visualizar sus resultados y evaluar el ajuste de los modelos.
Para esto haremos uso de la encuesta CASEN (2020), la mayor encuesta de hogares realizada en Chile, a cargo del Ministerio de Desarrollo Social, de carácter transversal y multipropósito, es el principal instrumento de medición socioeconómica para el diseño y evaluación de la política social. Permite conocer periódicamente la situación socioeconómica de los hogares y de la población que reside en viviendas particulares, a través de preguntas referidas a composición familiar, educación, salud, vivienda, trabajo e ingresos, entre otros aspectos.
1. Carga y preparación de la base de datos.
library(haven)
temp <- tempfile() #Creamos un archivo temporal
download.file("http://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/casen/2020/Casen_en_Pandemia_2020_revisada202209.sav.zip",temp) #descargamos los datos
casen <- haven::read_sav(unz(temp, "Casen_en_Pandemia_2020_revisada202209.sav")) #cargamos los datos
unlink(temp); remove(temp) #eliminamos el archivo temporal
Para ejecutar un modelo de regresión logística necesitamos que nuestra variable dependiente esté codificada con valores 0 y 1. En este caso transformaremos la variable pobreza, que cuenta con tres valores, a una variable dicotómica donde 0 es no pobre y 1 es pobre.
table(as_factor(casen$pobreza))
##
## Pobres extremos Pobres no extremos No pobres
## 8435 12862 164042
casen$pobre<-car::recode(casen$pobreza,"1:2=1;3=0")
Además filtraremos la base de datos para quedarnos solo con las jefaturas de hogar, de modo de tener solo un caso por hogar.
casen<-casen[casen$pco1==1,]
2. Estimación del modelo e interpretación de coeficientes
Para estimar un modelo de regresión logística binaria se utiliza el comando glm, que estima un modelo lineal generalizado. En este caso, el argumento family = “binomial” especifica que se está ajustando un modelo de regresión logística binaria.
“glm” es la función utilizada para ajustar un modelo de regresión logística en R. “pobre” es la variable dependiente, mientras que “sexo” y “edad” son las variables independientes. “as_factor” es una función utilizada para convertir la variable categórica “sexo” en un factor. “data” especifica el conjunto de datos que se utilizará para ajustar el modelo. “family = “binomial”” especifica que se está ajustando un modelo de regresión logística, es decir, que la variable dependiente es binaria.
library(texreg)
#para ver el output en la consola de R, reemplazar función htmlreg por screenreg
htmlreg(glm(pobre~as_factor(sexo)+edad, data=casen, family = "binomial"),
custom.coef.names = c("Intercepto","Mujer (ref.hombre)","Edad"),
custom.model.names = "Pobreza según sexo JH",single.row = T)
| Pobreza según sexo JH | |
|---|---|
| Intercepto | -1.07 (0.05)*** |
| Mujer (ref.hombre) | 0.39 (0.03)*** |
| Edad | -0.03 (0.00)*** |
| AIC | 40182.30 |
| BIC | 40209.45 |
| Log Likelihood | -20088.15 |
| Deviance | 40176.30 |
| Num. obs. | 62911 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
Interpretación:
Este bloque de código estima un modelo de regresión logística que busca predecir la probabilidad de que un hogar se encuentre en situación de pobreza, en función de características del jefe de hogar, en particular sexo (codificada como una variable factor) y edad. as_factor convierte la variable sexo en una variable factor, para poder utilizarla como variable independiente en el modelo de regresión logística.
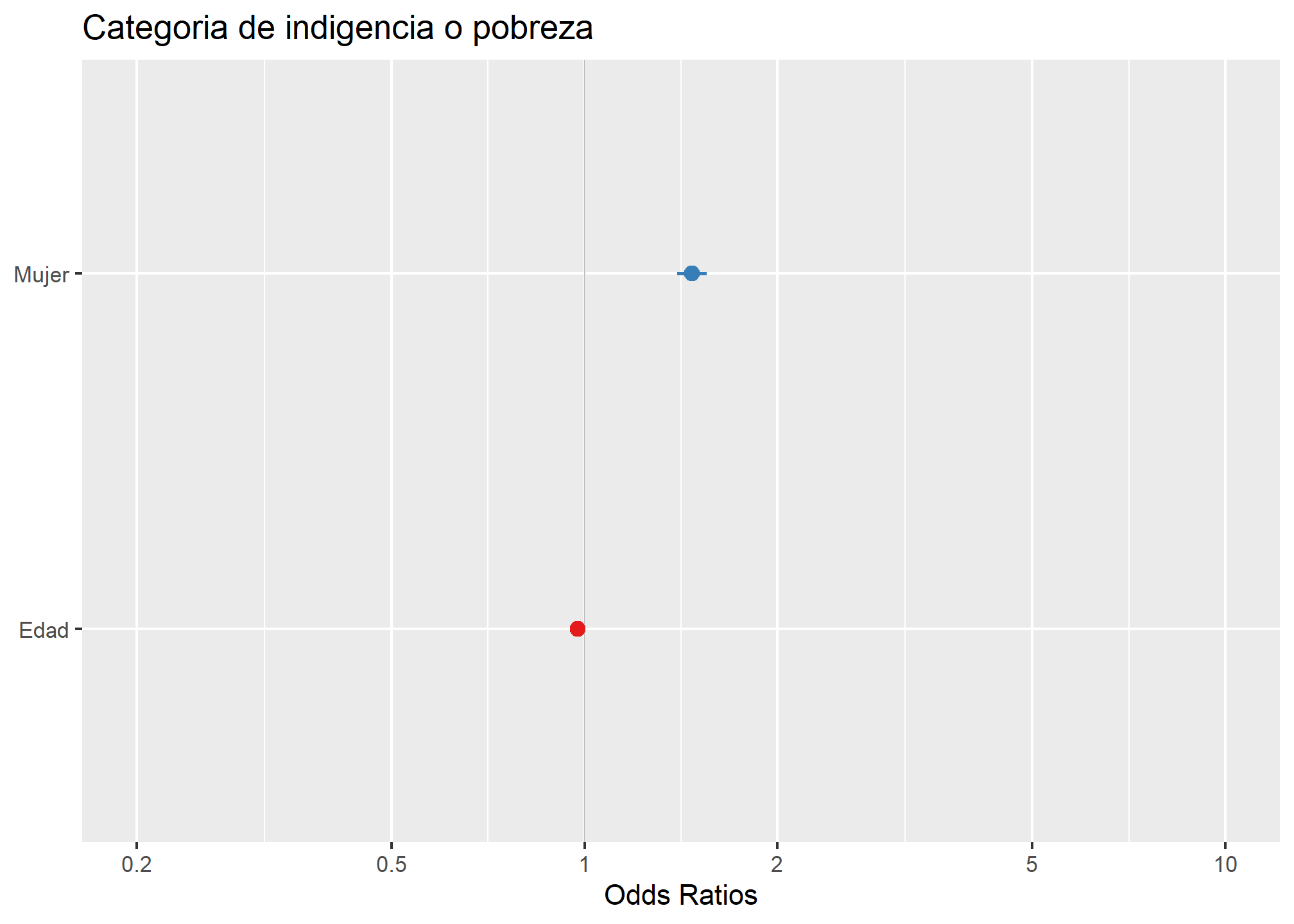
La variable “Mujer” (ref.hombre) tiene un coeficiente de 0.39 (0.03)***, lo que indica que los hogares con jefatura femenina tienen mayores probabilidades de encontrarse en situación de pobreza que los con jefatura masculina. En concreto, las odds (razón de probabilidades) de pobreza para una hogar con jefatura femenina son exp(0.39) = 1.48 veces mayores que las de uno con jefatura masculina, manteniendo constantes el resto de variables.
La variable “Edad” tiene un coeficiente de -0.03 (0.00)***, lo que indica que a medida que aumenta la edad del jefe de hogar, disminuyen las probabilidades de que el hogar se encuentre en situación de pobreza. En concreto, las odds de pobreza disminuyen en un factor de exp(-0.03) = 0.97, es decir en un 3%, por cada año de aumento en la edad del jefe de hogar, manteniendo constantes las demás variables.
modelo2<-glm(pobre~as_factor(sexo)+edad, data=casen, family = "binomial")
or <- texreg::extract(modelo2)
or@coef <- exp(or@coef)
htmlreg(or,
custom.coef.names = c("Intercepto","Mujer (ref.hombre)","Edad"),
custom.model.names = "Pobreza según sexo JH",single.row = T)
| Pobreza según sexo JH | |
|---|---|
| Intercepto | 0.34 (0.05)*** |
| Mujer (ref.hombre) | 1.47 (0.03)*** |
| Edad | 0.97 (0.00)*** |
| AIC | 40182.30 |
| BIC | 40209.45 |
| Log Likelihood | -20088.15 |
| Deviance | 40176.30 |
| Num. obs. | 62911 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |
A continuación, se utilizan las funciones “texreg::extract” y “exp” para obtener los ORs (odds ratios) y sus intervalos de confianza del modelo y, posteriormente, se utiliza la función “htmlreg” para mostrar los resultados en formato HTML.
3. Ajuste del modelo
Como vimos durante la clase, la interpretación de ajuste de los modelos de regresión logística tiene una orientación principalmente comparativa.
A continuación, se comparan los modelos utilizando el criterio estadístico de la prueba de razón de verosimilitud, utilizando la función “anova”. Para esto debemos guardar los modelos estimados como objetos.
“modelonulo” es un modelo nulo que sólo incluye el intercepto. “anova” se utiliza para comparar modelos ajustados y obtener la prueba de razón de verosimilitud. En este caso, se están comparando los modelos “modelonulo” y “modelo1”, y se especifica el test utilizado como “Chisq”.
modelonulo<-glm(pobre~1, data=casen, family = "binomial")
modelo1<-glm(pobre~as_factor(sexo), data=casen, family = "binomial")
modelo2<-glm(pobre~as_factor(sexo)+edad, data=casen, family = "binomial")
anova(modelonulo,modelo1, test ="Chisq")
## Analysis of Deviance Table
##
## Model 1: pobre ~ 1
## Model 2: pobre ~ as_factor(sexo)
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 62910 41314
## 2 62909 41071 1 243.1 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
En este caso, se están comparando los modelos “modelo1” y “modelo2”.
anova(modelo1,modelo2, test ="Chisq")
## Analysis of Deviance Table
##
## Model 1: pobre ~ as_factor(sexo)
## Model 2: pobre ~ as_factor(sexo) + edad
## Resid. Df Resid. Dev Df Deviance Pr(>Chi)
## 1 62909 41071
## 2 62908 40176 1 894.27 < 2.2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Por último, se utiliza la función “PseudoR2” del paquete “DescTools” para obtener los pseudo-R cuadrados de McFadden para cada modelo.
library(DescTools)
PseudoR2(modelo1,which="McFadden")
## McFadden
## 0.005884247
PseudoR2(modelo2,which="McFadden")
## McFadden
## 0.02753019
4. Visualización de resultados
El código anterior utiliza la función plot_model() de la librería sjPlot para generar un gráfico de visualización de los resultados del modelo de regresión logística modelo2 ajustado previamente.
La función plot_model() utiliza por defecto el tipo de gráfico “int” que muestra la interacción entre las variables predictoras en el eje X y la probabilidad ajustada de la variable respuesta en el eje Y. En este caso, la variable respuesta es la pobreza y las variables predictoras son el sexo y la edad.
Además, el código establece el color de la línea vertical para el valor medio de la variable edad en “grey”.
El gráfico muestra dos líneas: una para cada valor de la variable sexo (0 y 1), que representan la probabilidad ajustada de pobreza para cada valor de edad, controlando por la variable sexo. El gráfico permite visualizar la relación entre las variables predictoras y la variable respuesta de una manera más intuitiva. Por ejemplo, se puede ver que la probabilidad de pobreza es mayor para las mujeres en todas las edades, pero la brecha de género se reduce a medida que aumenta la edad.
En resumen, el código utiliza la función plot_model() para generar un gráfico que permite visualizar de manera intuitiva los resultados del modelo de regresión logística ajustado anteriormente.
library(sjPlot)
plot_model(modelo2,vline.color = "grey")
## Profiled confidence intervals may take longer time to compute.
## Use `ci_method="wald"` for faster computation of CIs.