Análisis Factorial Confirmatorio con R
Este análisis se lleva a cabo con el objetivo de verificar la estructura factorial sugerida por una teoría o un modelo en particular.
Primero, debemos asegurarnos de tener todos los paquetes necesarios instalados y cargados. Utilizaremos haven para importar datos, lavaan para estimar el Modelo de Ecuaciones Estructurales (SEM), semPlot para crear gráficos de SEM y semTable para producir tablas de SEM.
# Carga paquetes
library(haven) # importar SPSS, Stata, etc.
library(lavaan) # estimar SEM
## This is lavaan 0.6-15
## lavaan is FREE software! Please report any bugs.
library(semPlot) # graficar SEM
library(semTable) # tablas SEM
Posteriormente, importamos los datos que vamos a analizar. En este caso, los datos están almacenados en un archivo .sav de SPSS llamado “base_ideologia_afc.sav”. Lo importamos utilizando la función read_spss() del paquete haven.
# Importar datos
#datos <- read_spss("base_ideologia_afc.sav")
datos <- read_sav(url("https://github.com/Clases-GabrielSotomayor/pruebapagina/raw/master/content/example/input/data/base_ideologia_afc.sav"))
A continuación, definimos el modelo de medición para nuestro Análisis Factorial Confirmatorio (AFC). Estamos definiendo dos factores latentes (“autoritarismo” y “dominancia”) y tres ítems observables para cada factor. El operador =~ se utiliza para indicar las relaciones entre los factores y los ítems.
# Definir modelo de medición
mod_conf <- 'autoritarismo =~ aut1 + aut2 + aut3
dominancia =~ dom1 + dom2 + dom3'
Una vez definido el modelo, lo ajustamos utilizando la función cfa() del paquete lavaan. Como argumentos, le pasamos el modelo y los datos.
# Ajustar modelo CFA
mod_conf_afc <- cfa(mod_conf, data = datos)
Para ver un resumen de los resultados del modelo, utilizamos la función summary(). Hemos establecido standardized = TRUE para obtener las cargas factoriales estandarizadas, que son independientes de la escala de las variables observables. Además, fit.measures = TRUE se utiliza para mostrar los índices de ajuste del modelo, que nos indican cuán bien nuestro modelo especificado se ajusta a los datos.
# Resultados
## Salida general
summary(mod_conf_afc,
standardized = TRUE, # mostrar cargas estandarizadas
fit.measures = TRUE) # mostrar índices de ajuste extendidos
## lavaan 0.6.15 ended normally after 29 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of model parameters 13
##
## Number of observations 176
##
## Model Test User Model:
##
## Test statistic 12.332
## Degrees of freedom 8
## P-value (Chi-square) 0.137
##
## Model Test Baseline Model:
##
## Test statistic 650.010
## Degrees of freedom 15
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.993
## Tucker-Lewis Index (TLI) 0.987
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -1682.172
## Loglikelihood unrestricted model (H1) NA
##
## Akaike (AIC) 3390.345
## Bayesian (BIC) 3431.561
## Sample-size adjusted Bayesian (SABIC) 3390.393
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.055
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.113
## P-value H_0: RMSEA <= 0.050 0.384
## P-value H_0: RMSEA >= 0.080 0.282
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.049
##
## Parameter Estimates:
##
## Standard errors Standard
## Information Expected
## Information saturated (h1) model Structured
##
## Latent Variables:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## autoritarismo =~
## aut1 1.000 1.646 0.907
## aut2 0.921 0.060 15.457 0.000 1.517 0.887
## aut3 0.929 0.069 13.502 0.000 1.530 0.803
## dominancia =~
## dom1 1.000 1.201 0.919
## dom2 1.096 0.080 13.729 0.000 1.316 0.882
## dom3 0.861 0.084 10.298 0.000 1.034 0.685
##
## Covariances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## autoritarismo ~~
## dominancia 0.678 0.174 3.891 0.000 0.343 0.343
##
## Variances:
## Estimate Std.Err z-value P(>|z|) Std.lv Std.all
## .aut1 0.582 0.129 4.504 0.000 0.582 0.177
## .aut2 0.623 0.117 5.319 0.000 0.623 0.213
## .aut3 1.291 0.170 7.598 0.000 1.291 0.356
## .dom1 0.264 0.083 3.181 0.001 0.264 0.155
## .dom2 0.494 0.108 4.585 0.000 0.494 0.222
## .dom3 1.209 0.142 8.484 0.000 1.209 0.531
## autoritarismo 2.711 0.364 7.454 0.000 1.000 1.000
## dominancia 1.442 0.196 7.360 0.000 1.000 1.000
Además, podemos utilizar la función fitmeasures() para ver solo los índices de ajuste específicos que nos interesan.
# Ver solo índices de ajuste
fitmeasures(mod_conf_afc,
fit.measures = c("chisq", "df", "pvalue",
"cfi", "rmsea"))
## chisq df pvalue cfi rmsea
## 12.332 8.000 0.137 0.993 0.055
Después, creamos un diagrama de nuestro modelo con la función semPaths() del paquete semPlot.
# Diagrama modelo
semPaths(mod_conf_afc, # modelo ajustado
what = "std", # mostrar cargas estandarizadas
label.cex = 1, edge.label.cex = 1, # tamaño flechas y caracteres
residuals = FALSE, # no mostrar residuos
edge.color = "black") # color flechas
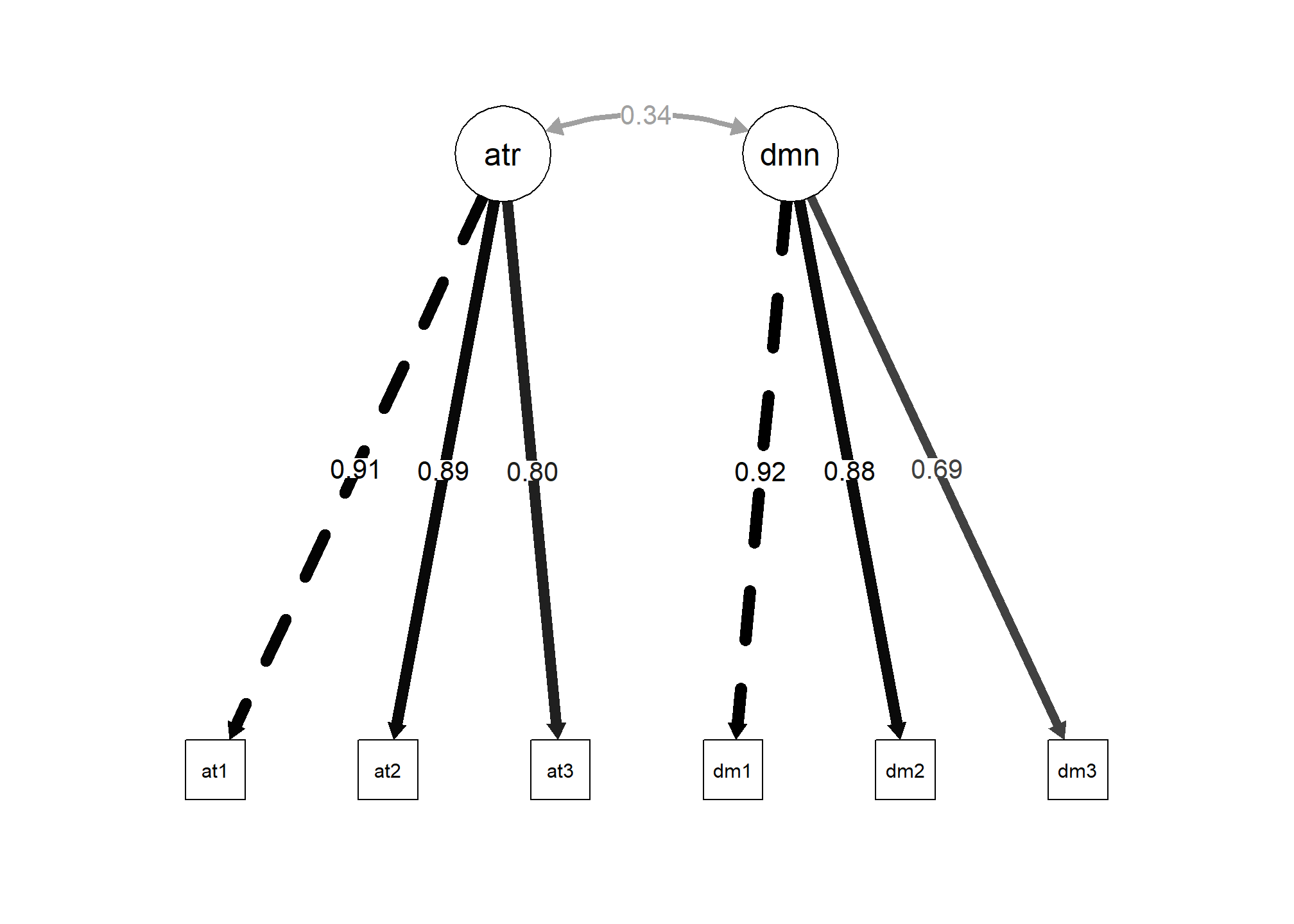 En el gráfico anterior, las flechas representan las relaciones causales sugeridas por el modelo y las cargas factoriales estandarizadas se muestran a lo largo de las flechas.
En el gráfico anterior, las flechas representan las relaciones causales sugeridas por el modelo y las cargas factoriales estandarizadas se muestran a lo largo de las flechas.
A continuación, estandarizamos las variables observadas utilizando la función scale(), lo que permite hacer comparaciones más justas entre las variables.
# Estandarizar variables observadas
datos.std <- scale(datos)
Luego ajustamos nuevamente el modelo CFA, pero esta vez utilizando los datos estandarizados.
## Crear objeto con mismo modelo pero estandarizado
mod_conf_afc_std <- cfa(mod_conf,
std.lv = TRUE,
meanstructure = TRUE,
data = datos.std)
Después, creamos y guardamos una tabla de los resultados en formato HTML utilizando la función semTable().
## Crear y guardar tabla en formato html
semTable(mod_conf_afc_std, type = "html",
file = "resultados_cfa_ideologia",
paramSets = c("loadings",
"latentcovariances",
"fits"))
| Model | ||||
| Estimate | Std. Err. | z | p | |
| Factor Loadings | ||||
| autoritarismo | ||||
| aut1 | 0.90 | 0.06 | 14.91 | .000 |
| aut2 | 0.88 | 0.06 | 14.41 | .000 |
| aut3 | 0.80 | 0.06 | 12.47 | .000 |
| dominancia | ||||
| dom1 | 0.92 | 0.06 | 14.72 | .000 |
| dom2 | 0.88 | 0.06 | 13.87 | .000 |
| dom3 | 0.68 | 0.07 | 9.96 | .000 |
| Latent Covariances | ||||
| autoritarismo w/dominancia | 0.34 | 0.07 | 4.62 | .000 |
| Fit Indices | ||||
| χ2 | 12.33(8) | .137 | ||
| CFI | 0.99 | |||
| TLI | 0.99 | |||
| RMSEA | 0.06 | |||
| +Fixed parameter | ||||
Primero, examinamos las cargas factoriales (o “Factor Loadings”), que representan las correlaciones entre cada ítem y el factor correspondiente. Los valores varían entre -1 y +1, donde los valores más cercanos a +1 o -1 indican una relación más fuerte entre el ítem y el factor.
Para “autoritarismo”, todos los ítems (aut1, aut2, aut3) tienen cargas factoriales altas, entre 0.80 y 0.90, lo que indica que están fuertemente relacionados con el factor “autoritarismo”. Todos estos resultados son estadísticamente significativos (p < .000).
Para “dominancia”, los ítems (dom1, dom2, dom3) también muestran cargas factoriales relativamente altas, variando de 0.68 a 0.92, sugiriendo una fuerte relación con el factor “dominancia”. De nuevo, todos los resultados son estadísticamente significativos (p < .001).
En segundo lugar, examinamos la covarianza entre los factores latentes (o “Latent Covariances”). Aquí, la covarianza entre “autoritarismo” y “dominancia” es de 0.34. Esto sugiere una relación positiva moderada entre los dos factores, y este resultado es estadísticamente significativo (p < .001).
Finalmente, examinamos los índices de ajuste del modelo (o “Fit Indices”). Estos índices evalúan qué tan bien nuestro modelo se ajusta a los datos observados. Los índices incluyen el chi cuadrado (χ2), el Índice de Ajuste Comparativo (CFI), el Índice de Ajuste no Normado (TLI) y el Error Cuadrático Medio de Aproximación (RMSEA).
El valor de χ2 es de 12.33 con 8 grados de libertad y un p-valor de 0.137. Un p-valor superior a 0.05 sugiere que el modelo se ajusta bien a los datos.
El CFI y el TLI son ambos 0.99. Estos índices varían de 0 a 1, y los valores superiores a 0.95 generalmente indican un buen ajuste del modelo a los datos.
El RMSEA es de 0.06. Los valores de RMSEA menores a 0.08 suelen considerarse como una indicación de un buen ajuste del modelo.
En resumen, los resultados sugieren que el modelo propuesto se ajusta bien a los datos, y las cargas factoriales indican que cada ítem se relaciona fuertemente con el factor correspondiente.
Desde la consola de R puedes ver la tabla abriendo el archivo HTML generado o utilizando la función browseURL().
browseURL("resultados_afc_ideologia.html")
El siguiente paso es calcular las comunalidades, que representan la proporción de la varianza de cada variable observable explicada por los factores. Para esto, utilizamos la función inspect() con el argumento what = “rsquare”.
# Comunalidades
inspect(mod_conf_afc, what = "rsquare")
## aut1 aut2 aut3 dom1 dom2 dom3
## 0.823 0.787 0.644 0.845 0.778 0.469
Por último, revisamos los índices de modificación, que nos dan sugerencias sobre cómo mejorar el ajuste del modelo. Mostramos los índices en orden decreciente para identificar primero los cambios potencialmente más impactantes.
# Índices de modificación
## Mostrar 'mi' en orden decreciente
modificationindices(mod_conf_afc, sort. = T)
## lhs op rhs mi epc sepc.lv sepc.all sepc.nox
## 18 autoritarismo =~ dom3 6.437 -0.152 -0.250 -0.165 -0.165
## 34 dom1 ~~ dom2 6.437 -0.982 -0.982 -2.719 -2.719
## 30 aut2 ~~ dom3 4.180 -0.170 -0.170 -0.196 -0.196
## 26 aut1 ~~ dom3 1.813 0.116 0.116 0.138 0.138
## 33 aut3 ~~ dom3 1.536 -0.133 -0.133 -0.106 -0.106
## 32 aut3 ~~ dom2 1.035 0.081 0.081 0.102 0.102
## 35 dom1 ~~ dom3 0.846 0.175 0.175 0.310 0.310
## 17 autoritarismo =~ dom2 0.846 0.044 0.072 0.048 0.048
## 28 aut2 ~~ dom1 0.840 0.049 0.049 0.120 0.120
## 36 dom2 ~~ dom3 0.418 0.131 0.131 0.169 0.169
## 16 autoritarismo =~ dom1 0.418 0.027 0.045 0.034 0.034
## 27 aut2 ~~ aut3 0.379 0.202 0.202 0.225 0.225
## 19 dominancia =~ aut1 0.379 0.046 0.056 0.031 0.031
## 31 aut3 ~~ dom1 0.323 -0.039 -0.039 -0.066 -0.066
## 21 dominancia =~ aut3 0.244 -0.044 -0.053 -0.028 -0.028
## 22 aut1 ~~ aut2 0.244 -0.223 -0.223 -0.370 -0.370
## 25 aut1 ~~ dom2 0.097 -0.020 -0.020 -0.037 -0.037
## 20 dominancia =~ aut2 0.056 -0.017 -0.020 -0.012 -0.012
## 23 aut1 ~~ aut3 0.056 -0.087 -0.087 -0.100 -0.100
## 24 aut1 ~~ dom1 0.009 -0.005 -0.005 -0.013 -0.013
## 29 aut2 ~~ dom2 0.005 0.005 0.005 0.008 0.008