Análisis Factorial Exploratorio I
0. Objetivo del práctico
El objetivo de este práctico es revisar como realizar la comprobación de supuestos y tratamiento de variables para la realización de un Análisis factorial Exploratorio.
1. Carga y gestión de datos
En primer lugar, cargaremos una base de datos de PNUD 2015, que incluye los siguientes ítem. Con estos esperamos revisar si existen estructuras latentes en como las personas evalúan las oportunidades que entrega Chile.
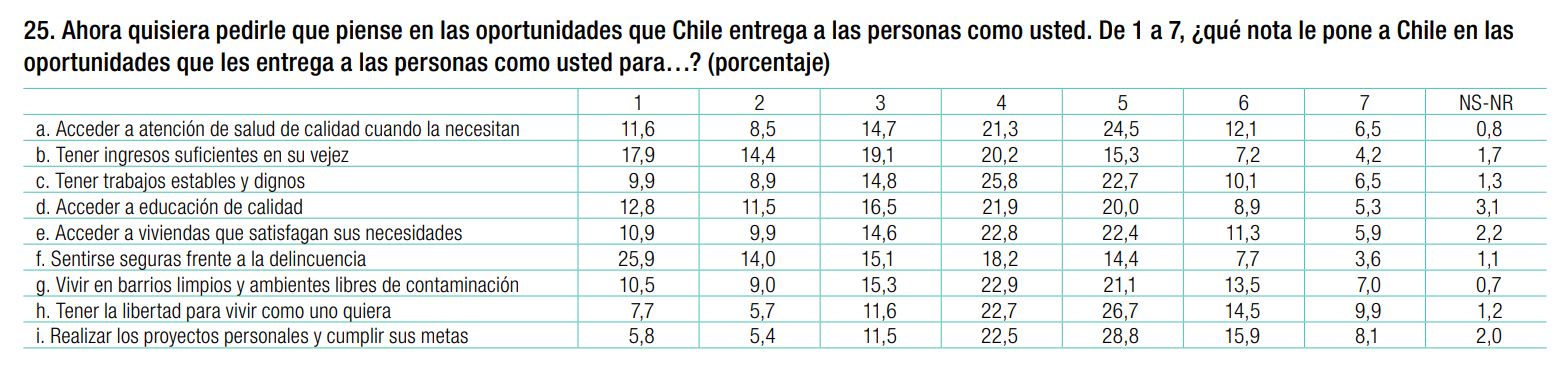
Estos datos están en formato csv (comma separated value), por lo cual podemos leerlos con la función read.csv2 incluida con r base.
#cargamos los datos
datos <- read.csv2("https://raw.githubusercontent.com/Clases-GabrielSotomayor/pruebapagina/master/static/slides/data/EjemploAF.csv")
A continuación, revisamos los datos y daremos por perdidos los valores no sabe y no responde.
# 3. DEFINIR VALORES PERDIDOS para Las variables, intervalares discretas de 7 categorias de las base de Datos PNUD 2015
summary(datos)
## SALUD INGR TRAB EDUC
## Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:3.000 1st Qu.:2.000 1st Qu.:3.000 1st Qu.:3.000
## Median :4.000 Median :3.000 Median :4.000 Median :4.000
## Mean :4.107 Mean :3.503 Mean :4.099 Mean :3.976
## 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:5.000
## Max. :9.000 Max. :9.000 Max. :9.000 Max. :9.000
## VIVI SEGUR MEDIO LIBER
## Min. :1.000 Min. :1.000 Min. :1.000 Min. :1.000
## 1st Qu.:3.000 1st Qu.:1.000 1st Qu.:3.000 1st Qu.:4.000
## Median :4.000 Median :3.000 Median :4.000 Median :5.000
## Mean :4.078 Mean :3.235 Mean :4.182 Mean :4.525
## 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:5.000 3rd Qu.:6.000
## Max. :9.000 Max. :9.000 Max. :9.000 Max. :9.000
## PROYE
## Min. :1.000
## 1st Qu.:4.000
## Median :5.000
## Mean :4.601
## 3rd Qu.:6.000
## Max. :9.000
#Categorizar como NA 8 y 9 (NS/NR).
datos[datos==9] <- NA
datos[datos==8] <- NA
A continuación, exploramos los datos para conocer sus medias y distribución. En este punto es relevante revisar si existe mucha diferencia en sus niveles de variabilidad, ya que esto afectara los resultados del Análisis Factorial Exploratorio.
# 4. ANALISIS DESCRIPTIVO DE LAS VARIABLES.
library(summarytools)
print(dfSummary(datos, headings = FALSE, method = "render"))
##
## -------------------------------------------------------------------------------------------
## No Variable Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- ----------- ----------------------- -------------------- --------- --------- ---------
## 1 SALUD Mean (sd) : 4.1 (1.8) 1 : 218 (12.3%) II 1769 11
## [integer] min < med < max: 2 : 143 ( 8.1%) I (99.4%) (0.6%)
## 1 < 4 < 7 3 : 251 (14.2%) II
## IQR (CV) : 2 (0.4) 4 : 358 (20.2%) IIII
## 5 : 415 (23.5%) IIII
## 6 : 234 (13.2%) II
## 7 : 150 ( 8.5%) I
##
## 2 INGR Mean (sd) : 3.4 (1.7) 1 : 335 (19.1%) III 1752 28
## [integer] min < med < max: 2 : 235 (13.4%) II (98.4%) (1.6%)
## 1 < 3 < 7 3 : 343 (19.6%) III
## IQR (CV) : 3 (0.5) 4 : 340 (19.4%) III
## 5 : 274 (15.6%) III
## 6 : 138 ( 7.9%) I
## 7 : 87 ( 5.0%)
##
## 3 TRAB Mean (sd) : 4 (1.7) 1 : 178 (10.2%) II 1749 31
## [integer] min < med < max: 2 : 161 ( 9.2%) I (98.3%) (1.7%)
## 1 < 4 < 7 3 : 265 (15.2%) III
## IQR (CV) : 2 (0.4) 4 : 433 (24.8%) IIII
## 5 : 380 (21.7%) IIII
## 6 : 209 (11.9%) II
## 7 : 123 ( 7.0%) I
##
## 4 EDUC Mean (sd) : 3.8 (1.7) 1 : 227 (13.3%) II 1712 68
## [integer] min < med < max: 2 : 190 (11.1%) II (96.2%) (3.8%)
## 1 < 4 < 7 3 : 295 (17.2%) III
## IQR (CV) : 2 (0.5) 4 : 369 (21.6%) IIII
## 5 : 340 (19.9%) III
## 6 : 188 (11.0%) II
## 7 : 103 ( 6.0%) I
##
## 5 VIVI Mean (sd) : 4 (1.7) 1 : 208 (11.9%) II 1746 34
## [integer] min < med < max: 2 : 162 ( 9.3%) I (98.1%) (1.9%)
## 1 < 4 < 7 3 : 276 (15.8%) III
## IQR (CV) : 2 (0.4) 4 : 362 (20.7%) IIII
## 5 : 383 (21.9%) IIII
## 6 : 237 (13.6%) II
## 7 : 118 ( 6.8%) I
##
## 6 SEGUR Mean (sd) : 3.2 (1.8) 1 : 481 (27.3%) IIIII 1764 16
## [integer] min < med < max: 2 : 220 (12.5%) II (99.1%) (0.9%)
## 1 < 3 < 7 3 : 297 (16.8%) III
## IQR (CV) : 4 (0.6) 4 : 308 (17.5%) III
## 5 : 238 (13.5%) II
## 6 : 155 ( 8.8%) I
## 7 : 65 ( 3.7%)
##
## 7 MEDIO Mean (sd) : 4.1 (1.7) 1 : 188 (10.7%) II 1763 17
## [integer] min < med < max: 2 : 144 ( 8.2%) I (99.0%) (1.0%)
## 1 < 4 < 7 3 : 247 (14.0%) II
## IQR (CV) : 2 (0.4) 4 : 396 (22.5%) IIII
## 5 : 364 (20.6%) IIII
## 6 : 288 (16.3%) III
## 7 : 136 ( 7.7%) I
##
## 8 LIBER Mean (sd) : 4.5 (1.6) 1 : 140 ( 8.0%) I 1757 23
## [integer] min < med < max: 2 : 88 ( 5.0%) I (98.7%) (1.3%)
## 1 < 5 < 7 3 : 202 (11.5%) II
## IQR (CV) : 2 (0.4) 4 : 379 (21.6%) IIII
## 5 : 445 (25.3%) IIIII
## 6 : 325 (18.5%) III
## 7 : 178 (10.1%) II
##
## 9 PROYE Mean (sd) : 4.5 (1.6) 1 : 109 ( 6.2%) I 1746 34
## [integer] min < med < max: 2 : 94 ( 5.4%) I (98.1%) (1.9%)
## 1 < 5 < 7 3 : 202 (11.6%) II
## IQR (CV) : 2 (0.3) 4 : 370 (21.2%) IIII
## 5 : 466 (26.7%) IIIII
## 6 : 343 (19.6%) III
## 7 : 162 ( 9.3%) I
## -------------------------------------------------------------------------------------------
2. Comprobación de supuestos
En este bloque de código, se cargan las bibliotecas necesarias para realizar la comprobación de supuestos.
library(psych)
library(MVN)
Para la comprobación de supuestos partiremos por generar una base de datos listwise, es decir, en la que se eliminan todos los casos que tienen valores perdidos en alguno de los ítem. Esto es posible en este caso por el número moderado de casos perdidos existentes. Pasamos de tener 1780 casos a 1632.
# 5a. Crear una base solo con listwise (para test de Mardia)
datosLW <- na.omit(datos)
dim(datosLW)
## [1] 1632 9
A continuación, revisaremos la existencia de casos atípicos multivariantes a partir del cálculo y evaluación de la distancia de Mahalanobis. Primero se crean las medias para cada variable (mean) y la matriz de covarianzas (Sx) para calcular la distancia de mahalanobis con la función correspondiente.
Luego se calcula el valor p asociado con cada distancia de Mahalanobis D2 y se guarda como una nueva variable: datosLW$sigmahala=(1-pchisq(D2, 3)).
Finalmente se filtran los casos atípicos multivariantes según el valor p de la distancia de mahalanobis, y se elimina la variable creada en el paso anterior.
#Tratamiento de casos atipicos
mean<-colMeans(datosLW[1:9])
Sx<-cov(datosLW[1:9]) #matriz de varianza covariaza
D2<-mahalanobis(datosLW[1:9],mean,Sx)
datosLW$sigmahala=(1-pchisq(D2, 3))
datosLW<-datosLW[which(datosLW$sigmahala>0.001),]#dar por perdido o eliminar caso atipico
datosLW$sigmahala<-NULL
A continuación, utilizamos la función mvn para evaluar la normalidad multivariante y univariante en un conjunto de datos. Especificamos que utilice el test de Mardia para evaluar la existencia de normalidad multivariante en nuestros datos.
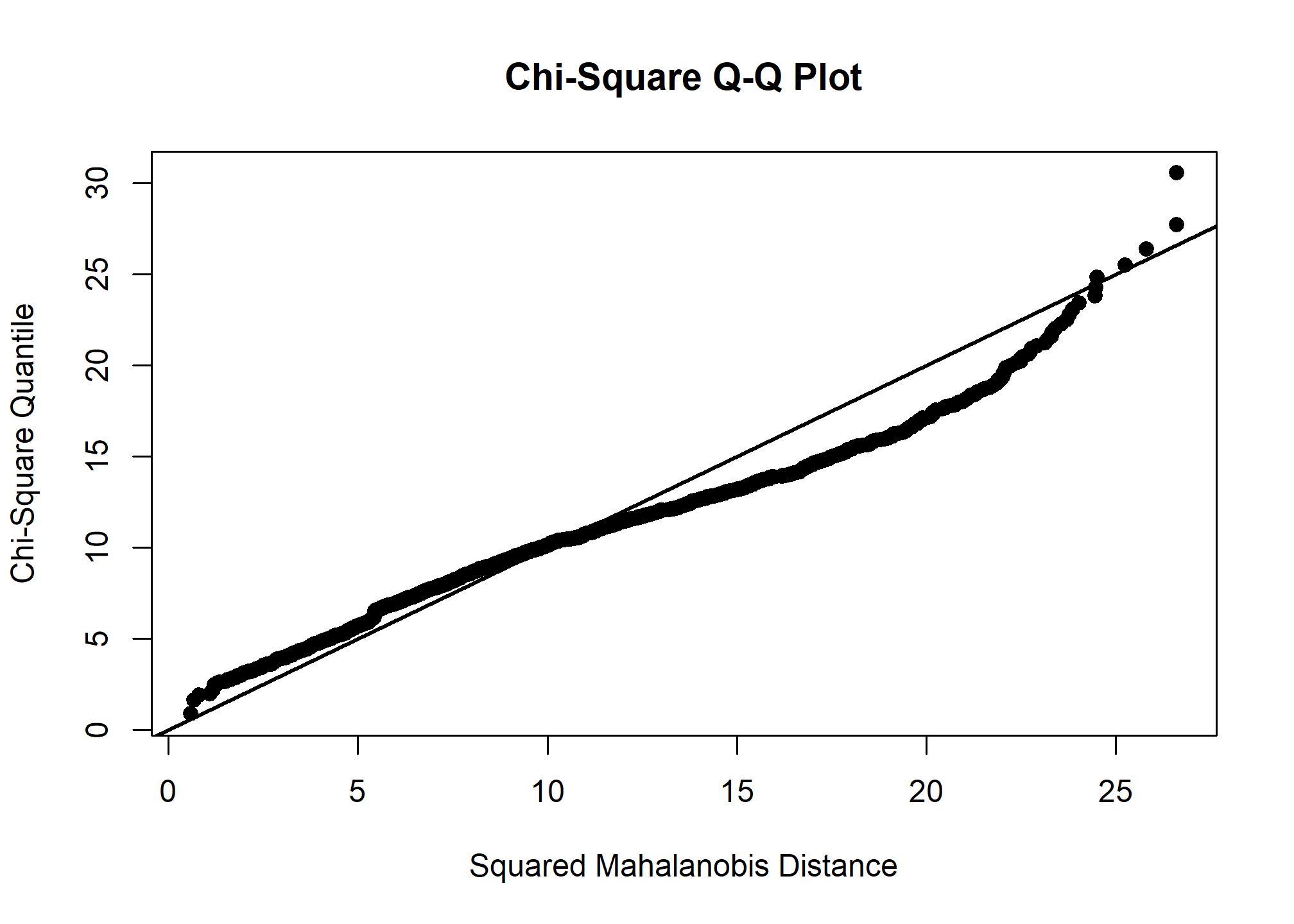
El output de esta función tiene 4 elementos: en gráfico q-q que compara la distribución multivariante de los datos con una normal, los resultados de la prueba de Mardia para evaluar la normalidad multivariante, los resultados de la prueba de Anderson-Darling para evaluar la normalidad univariante de cada variable en el conjunto de datos y estadísticas descriptivas para cada variable en el conjunto de datos, entre las que resulta particularmente relevante la asimetría, que en caso de no existir normalidad, se espera que se encuentra dentro del rango +-2.
#Test de Mardia.
MVN::mvn(datosLW,mvnTest = "mardia",multivariatePlot="qq")
## $multivariateNormality
## Test Statistic p value Result
## 1 Mardia Skewness 1024.97674314003 4.20675113139256e-124 NO
## 2 Mardia Kurtosis 13.6081361520113 0 NO
## 3 MVN <NA> <NA> NO
##
## $univariateNormality
## Test Variable Statistic p value Normality
## 1 Anderson-Darling SALUD 28.6413 <0.001 NO
## 2 Anderson-Darling INGR 26.6601 <0.001 NO
## 3 Anderson-Darling TRAB 26.5021 <0.001 NO
## 4 Anderson-Darling EDUC 25.5337 <0.001 NO
## 5 Anderson-Darling VIVI 26.1493 <0.001 NO
## 6 Anderson-Darling SEGUR 33.4689 <0.001 NO
## 7 Anderson-Darling MEDIO 27.4659 <0.001 NO
## 8 Anderson-Darling LIBER 32.7548 <0.001 NO
## 9 Anderson-Darling PROYE 33.7289 <0.001 NO
##
## $Descriptives
## n Mean Std.Dev Median Min Max 25th 75th Skew Kurtosis
## SALUD 1412 4.065864 1.667821 4 1 7 3 5 -0.25263651 -0.6874886
## INGR 1412 3.513456 1.679227 3 1 7 2 5 0.14764264 -0.8046420
## TRAB 1412 3.997875 1.603282 4 1 7 3 5 -0.15429604 -0.6120418
## EDUC 1412 3.859773 1.662577 4 1 7 3 5 -0.08589195 -0.7899976
## VIVI 1412 4.021955 1.635520 4 1 7 3 5 -0.17217851 -0.7308634
## SEGUR 1412 3.332861 1.760975 3 1 7 2 5 0.22988413 -0.9486602
## MEDIO 1412 4.107649 1.624502 4 1 7 3 5 -0.24817625 -0.6387453
## LIBER 1412 4.364023 1.598390 5 1 7 3 5 -0.45141365 -0.3765372
## PROYE 1412 4.435552 1.548446 5 1 7 4 6 -0.48952927 -0.2833381
Tanto el test de mardia como la prueba de normalidad univariante para cada variable dan cuenta de que no existe normalidad, lo cual debe tenerse en cuenta al seleccionar la forma de extracción de los factores. También nos indica que más adelante no será posible interpretar la preuba de esfericidad de Barlett para multicolinealdiad, ya que esta supone normalidad multivariante.
A pesar de que no existe normalidad multivariante, encontramos una asimetría moderada, por lo que es posible continuar con el análisis.
A continuación calculamos la matriz de correlaciones para evaluar la existencia de colinealidad. Esto es relevante porque es necesario que exista suficiente varianza común entre las variables para la extracción de factores comunes.
#Matriz de Correlaciones
#Uso de Pearson por caracteristicas de las variables (discretas de baja asimetria)
cor_datos<- cor(datosLW)
print(cor_datos)
## SALUD INGR TRAB EDUC VIVI SEGUR MEDIO
## SALUD 1.0000000 0.7420187 0.7061226 0.7355949 0.7108488 0.5813200 0.6403432
## INGR 0.7420187 1.0000000 0.7119460 0.7297410 0.7045040 0.6844146 0.6401415
## TRAB 0.7061226 0.7119460 1.0000000 0.7953929 0.7770609 0.5861336 0.6871631
## EDUC 0.7355949 0.7297410 0.7953929 1.0000000 0.8304784 0.6663916 0.7159214
## VIVI 0.7108488 0.7045040 0.7770609 0.8304784 1.0000000 0.6761304 0.7227902
## SEGUR 0.5813200 0.6844146 0.5861336 0.6663916 0.6761304 1.0000000 0.6529007
## MEDIO 0.6403432 0.6401415 0.6871631 0.7159214 0.7227902 0.6529007 1.0000000
## LIBER 0.6540362 0.6099701 0.7210026 0.7246200 0.7386788 0.5599566 0.7933515
## PROYE 0.6425699 0.6217780 0.7451753 0.7265637 0.7442531 0.5573235 0.7299445
## LIBER PROYE
## SALUD 0.6540362 0.6425699
## INGR 0.6099701 0.6217780
## TRAB 0.7210026 0.7451753
## EDUC 0.7246200 0.7265637
## VIVI 0.7386788 0.7442531
## SEGUR 0.5599566 0.5573235
## MEDIO 0.7933515 0.7299445
## LIBER 1.0000000 0.8582211
## PROYE 0.8582211 1.0000000
print(det(cor_datos))#Cercano a 0 correlacion multivariante
## [1] 0.0001593243
La matriz de correlaciones da cuenta de un alto nivel de correlación entre las variables. Como criterio general se espera que existan correlaciones de al menos 0,3.
El determinante de la matriz de correlaciones se calcula con la función det(). Un determinante cercano a 0 indica que existe correlación multivariante entre las variables. En este caso, el determinante es 0.0001593243, lo que sugiere que hay colinealidad entre las variables.
A continuación se presenta como calcular una matriz de correlaciones policóricas para el caso de estar trabajando con variables ordinales. En caso de variable dicotómicas (0-1) corresponde usar correlaciones tetracóricas mediante la función ‘tetrachoric()’.
#Probar con matriz policlorica en caso de estar trabajando con variables ordinales.
polychoric(datosLW)
## Call: polychoric(x = datosLW)
## Polychoric correlations
## SALUD INGR TRAB EDUC VIVI SEGUR MEDIO LIBER PROYE
## SALUD 1.00
## INGR 0.77 1.00
## TRAB 0.73 0.75 1.00
## EDUC 0.76 0.76 0.82 1.00
## VIVI 0.73 0.74 0.81 0.86 1.00
## SEGUR 0.62 0.72 0.63 0.71 0.72 1.00
## MEDIO 0.66 0.67 0.72 0.75 0.75 0.70 1.00
## LIBER 0.67 0.64 0.75 0.76 0.77 0.61 0.83 1.00
## PROYE 0.67 0.66 0.77 0.76 0.78 0.60 0.77 0.89 1.00
##
## with tau of
## 1 2 3 4 5 6
## SALUD -1.25 -0.89 -0.4184 0.164 0.85 1.5
## INGR -1.00 -0.55 0.0071 0.538 1.15 1.7
## TRAB -1.35 -0.88 -0.3934 0.277 0.93 1.6
## EDUC -1.21 -0.76 -0.2511 0.318 0.96 1.6
## VIVI -1.34 -0.86 -0.3591 0.207 0.88 1.6
## SEGUR -0.77 -0.39 0.0960 0.609 1.12 1.8
## MEDIO -1.34 -0.95 -0.4516 0.195 0.79 1.6
## LIBER -1.41 -1.11 -0.6436 -0.030 0.68 1.4
## PROYE -1.52 -1.18 -0.6947 -0.076 0.64 1.5
Por último, chequeamos la existencia de multicolinealidad. Con fines de presentar el código, se calcula la prueba de esfericidad de Bartlett, sin embargo esta no puede interpretarse de manera confiable, ya que esta presupone normalidad multivariante, la cual no existe en este caso.
La prueba de esfericidad de Bartlett evalúa si la matriz de correlaciones es significativamente diferente de la matriz de identidad. En otras palabras, contrasta la hipótesis nula de que las variables no están correlacionadas en absoluto (es decir, la matriz de correlaciones es igual a la matriz de identidad). La función toma los como argumento la matriz de correlaciones y el n.
# 5c. MULTICOLINEALIDAD
#Test de esfericidad de Bartlett. Contrastar la hipotesis Nula de Igualdad con Matriz identidad
print(cortest.bartlett(cor_datos,n = nrow(datosLW)))
## $chisq
## [1] 12305.07
##
## $p.value
## [1] 0
##
## $df
## [1] 36
En este caso, el valor chi-cuadrado es 12305.07 y el valor p es muy pequeño, lo que indica que se debe rechazar la hipótesis nula de que la matriz de correlaciones es igual a la matriz de identidad. Esto sugiere que hay correlaciones entre las variables y es apropiado continuar con el análisis factorial exploratorio.
La función KMO() calcula la medida de adecuación del muestreo de Kaiser-Meyer-Olkin (KMO) para evaluar la adecuación de los datos para el análisis factorial. La medida KMO varía entre 0 y 1, y valores más altos indican que el análisis factorial es más adecuado para los datos.
#KMO
KMO(datosLW)
## Kaiser-Meyer-Olkin factor adequacy
## Call: KMO(r = datosLW)
## Overall MSA = 0.94
## MSA for each item =
## SALUD INGR TRAB EDUC VIVI SEGUR MEDIO LIBER PROYE
## 0.95 0.93 0.96 0.95 0.95 0.93 0.94 0.89 0.92
El output incluye:
- Overall MSA: La medida KMO general para todo el conjunto de datos.
- MSA for each item: La medida KMO para cada variable en el conjunto de datos.
En este caso, la medida KMO general es 0.94, lo que indica una adecuación muy alta para el análisis factorial. Además, las medidas KMO para cada variable también son altas (entre 0.89 y 0.96), lo que sugiere que cada variable contribuye adecuadamente al análisis factorial.