3. Análisis de Regresión Lineal Múltiple
0. Objetivo del práctico
El objetivo de este práctico es presentar una introducción al Análisis de Regresión Lineal Múltiple, visualizar sus resultados y evaluar el ajuste de los modelos y el cumplimiento de los supuestos de la técnica.
Para esto haremos uso de la encuesta CASEN (2020), la mayor encuesta de hogares realizada en Chile, a cargo del Ministerio de Desarrollo Social, de carácter transversal y multipropósito, es el principal instrumento de medición socioeconómica para el diseño y evaluación de la política social. Permite conocer periódicamente la situación socioeconómica de los hogares y de la población que reside en viviendas particulares, a través de preguntas referidas a composición familiar, educación, salud, vivienda, trabajo e ingresos, entre otros aspectos.
Cargar paquetes a utilizar
Para iniciar se cargan los paquetes necesarios para realizar el análisis de regresión. Al utilizar la función p_load() del paquete “pacman”, si alguno de los paquetes no está instalado, se instalará automáticamente con la función install.packages(). Los paquetes utilizados son:
haven: para cargar archivos SPSS en R. texreg: para crear tablas de resumen de regresión. corrplot: para visualizar las correlaciones entre variables. coefplot: para crear gráficos de coeficientes de regresión. ggplot2: para crear gráficos. sjPlot: para crear tablas de resumen de regresión y gráficos. summarytools: para crear resúmenes de variables. dplyr: para manipulación de datos. lmtest: para pruebas de diagnóstico de regresión. sandwich: para estimar errores robustos en regresiones.
# Cargar paquetes a utilizar
if (!require("pacman")) install.packages("pacman")
## Loading required package: pacman
## Warning: package 'pacman' was built under R version 4.2.2
pacman::p_load(haven,texreg,corrplot,coefplot,ggplot2,sjPlot,summarytools,dplyr,
lmtest,sandwich)
Importar datos
A continuación se carga la base de datos de CASEN 2020. La base de datos se encuentra en la página web del Observatorio Social. La función read_spss() del paquete haven se utiliza para cargar la base de datos.
Primero, se descarga un archivo comprimido que contiene la base de datos desde la página web utilizando la función download.file(). Luego, se descomprime el archivo utilizando la función unz() y se carga la base de datos utilizando la función read_sav(). Finalmente, se elimina el archivo temporal que se creó durante el proceso de descarga y descompresión utilizando la función unlink() y remove().
temp <- tempfile() #Creamos un archivo temporal
download.file("http://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/casen/2020/Casen_en_Pandemia_2020_revisada202209.sav.zip",temp) #descargamos los datos
base <- haven::read_sav(unz(temp, "Casen_en_Pandemia_2020_revisada202209.sav")) #cargamos los datos
unlink(temp); remove(temp) #eliminamos el archivo temporal
Análisis previos
El análisis de regresión lineal requiere una variable dependiente continua, mientras que las variables independientes pueden corresponder a cualquier nivel de medición. Podemos revisar el tipo de datos de las variables que utilizaremos con la función “class()”
class(base$yautcor)
## [1] "numeric"
class(base$esc)
## [1] "numeric"
class(base$edad)
## [1] "numeric"
class(as_factor(base$sexo))
## [1] "factor"
Se utiliza la función dfSummary() del paquete summarytools para crear un resumen de las variables yautcor, esc, edad y sexo de la base de datos. El resumen incluye estadísticas descriptivas y de frecuencia.
print(dfSummary(base[,c("yautcor","esc","edad","sexo")], headings = FALSE, method = "render"))
##
## -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
## No Variable Label Stats / Values Freqs (% of Valid) Graph Valid Missing
## ---- -------------------------------------- --------------------------------------- -------------------------------- ----------------------- ------------------- ---------- ---------
## 1 yautcor Ingreso autónomo corregido Mean (sd) : 517331.5 (1163534) 15287 distinct values : 102165 83272
## [numeric] min < med < max: : (55.1%) (44.9%)
## 17 < 320000 < 225200000 :
## IQR (CV) : 425000 (2.2) :
## :
##
## 2 esc Años de escolaridad truncada (edad >= Mean (sd) : 11.3 (4.3) 23 distinct values : 148886 36551
## [numeric] 15) min < med < max: : (80.3%) (19.7%)
## 0 < 12 < 22 : .
## IQR (CV) : 6 (0.4) . : : : :
## . . : : : : : : .
##
## 3 edad Edad Mean (sd) : 38.4 (22.8) 108 distinct values . : : . . 185437 0
## [numeric] min < med < max: : : : : : : (100.0%) (0.0%)
## 0 < 37 < 110 : : : : : : .
## IQR (CV) : 38 (0.6) : : : : : : :
## : : : : : : : : .
##
## 4 sexo Sexo Min : 1 1 : 86096 (46.4%) IIIIIIIII 185437 0
## [haven_labelled, vctrs_vctr, double] Mean : 1.5 2 : 99341 (53.6%) IIIIIIIIII (100.0%) (0.0%)
## Max : 2
## -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
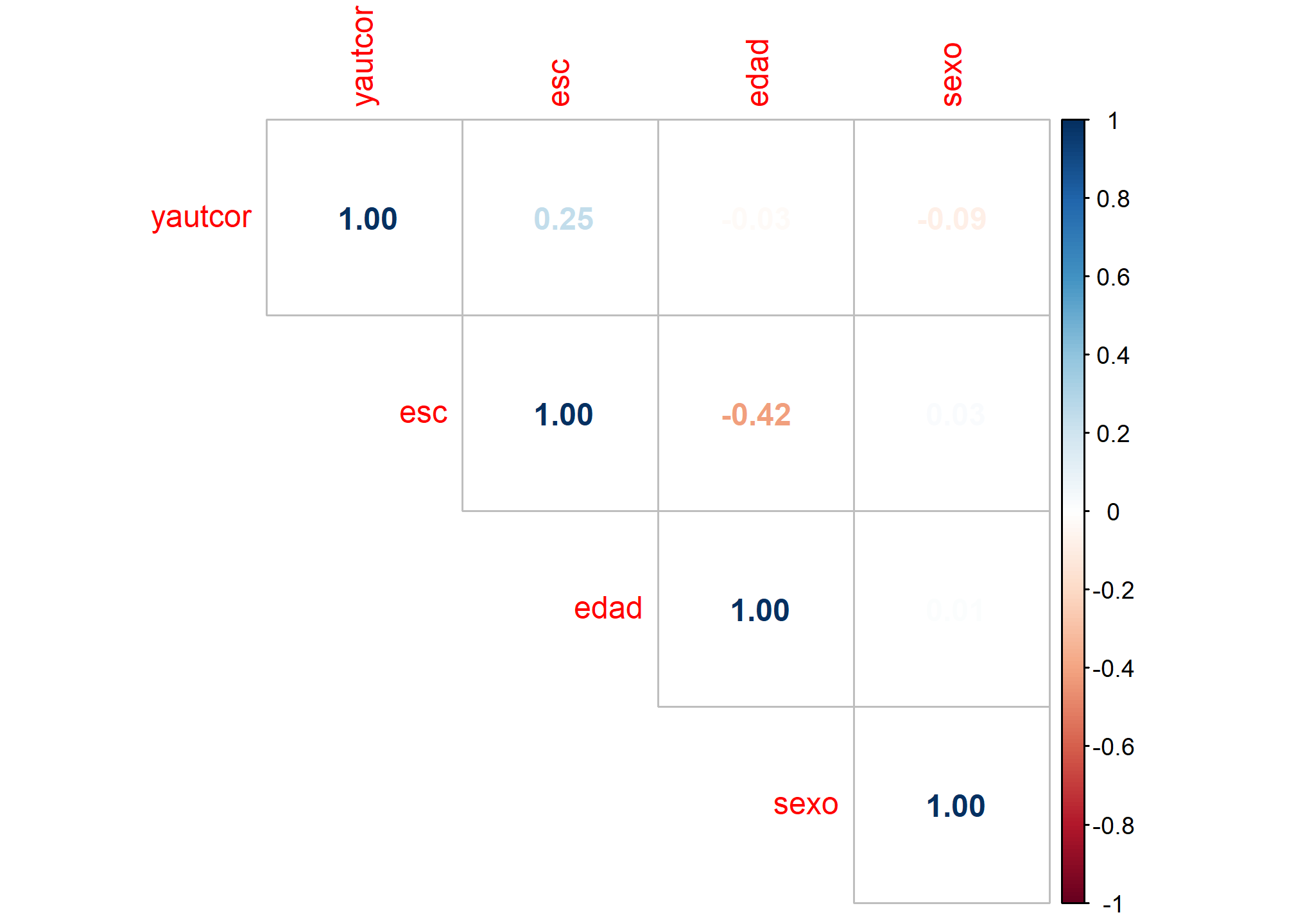
Realizamos un análisis de correlaciones bivariadas con el fin de revisar si existe una relación lineal entre la variable dependiente y las variables independientes, además de comprobar que no existan problemas de colinealidad entre estas últimas. Se calcula la matriz de correlaciones entre las variables yautcor, esc, edad y sexo utilizando la función cor(). La opción use=“complete.obs” se utiliza para omitir cualquier fila que contenga valores faltantes (NA). Luego, se asigna la matriz de correlaciones al objeto mc.
#correlaciones
cor(base[,c("yautcor","esc","edad","sexo")], use="complete.obs")
## yautcor esc edad sexo
## yautcor 1.00000000 0.24719354 -0.02556606 -0.08642795
## esc 0.24719354 1.00000000 -0.41626104 0.02755352
## edad -0.02556606 -0.41626104 1.00000000 0.01184122
## sexo -0.08642795 0.02755352 0.01184122 1.00000000
mc<-cor(base[,c("yautcor","esc","edad","sexo")], use="complete.obs")
Para visualizar las correlaciones de manera más clara, se utiliza la función corrplot() del paquete corrplot. La opción method = ‘number’ indica que se deben mostrar los valores de correlación en cada celda y type = ‘upper’ indica que solo se deben mostrar las celdas de la parte superior de la matriz (ya que la matriz es simétrica).
corrplot(mc, method = 'number', type = 'upper')
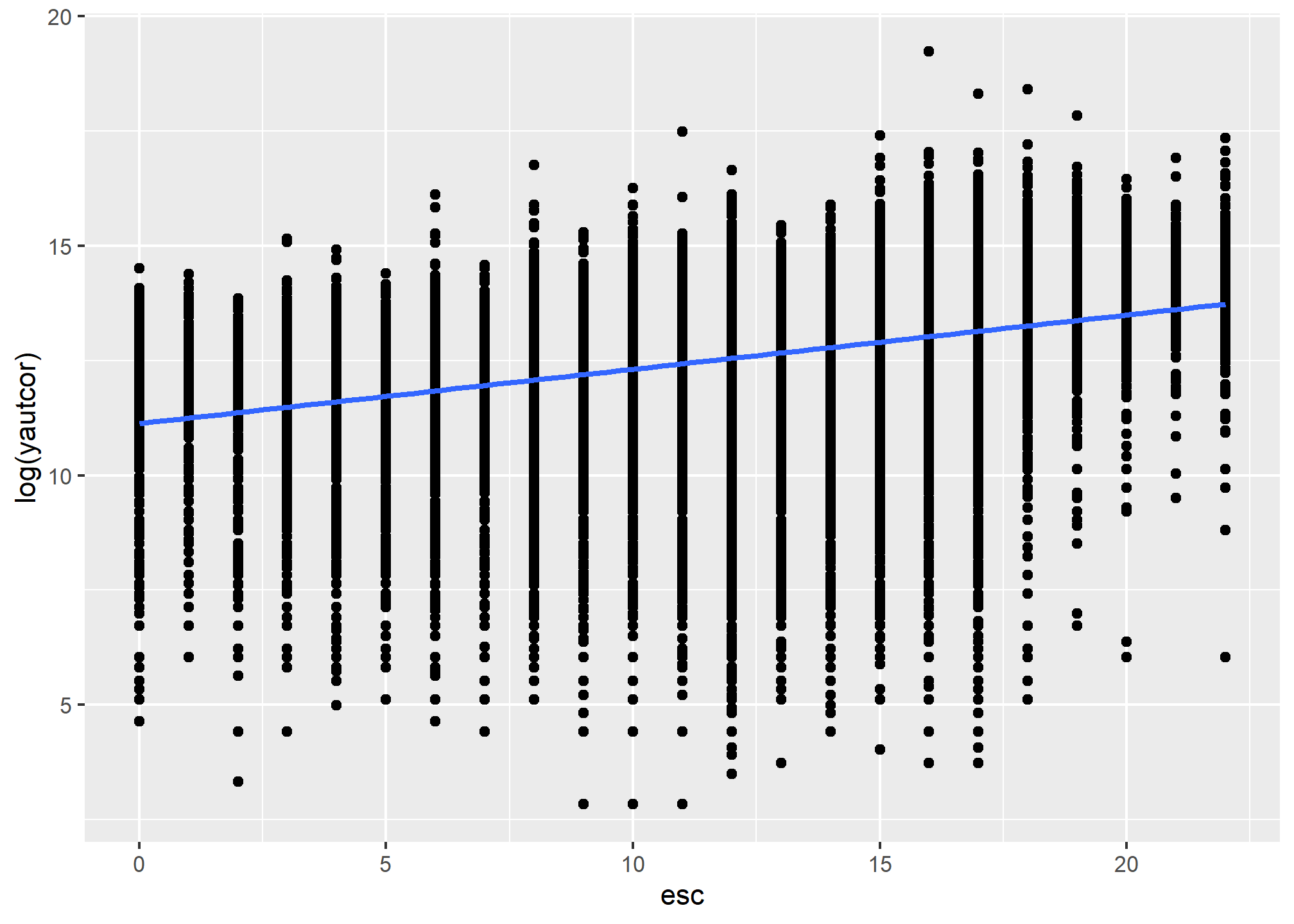
A continuación, usamos el paquete ggplot para obtener un gráfico que nos muestre la distribución del ingreso autónomo de acuerdo con la escolaridad. Dado que el ingreso tiene muchos casos extremos, aplicamos una transformación logarítmica log() para visualizar de mejor manera la relación entre las variables. Este gráfico nos permite observar la existencia de relación lineal entre las variables. Dicha visualización es relevante porque en algunos casos, dos variables pueden tener una baja correlación, pero estar relacionadas de manera no lineal, lo cual puede observarse mediante la visualización. El gráfico muestra que hay una relación lineal positiva entre yautcor y esc.
g=ggplot(base, aes(x=esc, y=log(yautcor))) +
geom_point()+ geom_smooth(method="lm", se=FALSE)
g
## `geom_smooth()` using formula = 'y ~ x'
Estimación del modelo
A continuación, se estima un modelo de regresión lineal simple (modelo1) que explique el ingreso autónomo en función de la escolaridad. Se utiliza la función lm() y se asigna el resultado a la variable modelo1. Luego, se utiliza la función summary() para obtener un resumen de los resultados.
Las variables del modelo de regresión deben presentarse como una formula, en que la variable dependiente se separa de las independientes con el caracter “~”.
modelo1 <- lm(yautcor~ esc,data = base)
summary(modelo1)
##
## Call:
## lm(formula = yautcor ~ esc, data = base)
##
## Residuals:
## Min 1Q Median 3Q Max
## -1230799 -337875 -131302 137567 224375890
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) -261505.5 10619.6 -24.62 <2e-16 ***
## esc 67851.0 853.8 79.47 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1142000 on 97031 degrees of freedom
## (88404 observations deleted due to missingness)
## Multiple R-squared: 0.0611, Adjusted R-squared: 0.06109
## F-statistic: 6315 on 1 and 97031 DF, p-value: < 2.2e-16
A continuación se calcula el coeficiente de determinación del modelo (R2).
1-var(modelo1$residuals)/
var(base$yautcor[!is.na(base$esc)&!is.na(base$edad)&!is.na(base$sexo)],na.rm=T)
## [1] 0.06110465
Luego estimamos modelos de regresión lineal múltiple. El modelo 2 incluye las variables independientes de escolaridad, edad y sexo codificado como factor. El modelo 3 es idéntico al modelo 2, excepto que se incluyen los factores de expansión de la encuesta.
modelo2 <- lm(yautcor~ esc+ edad+ as_factor(sexo),data = base)
modelo3 <- lm(yautcor~ esc+ edad+ as_factor(sexo),data = base,weights = expr)
Luego, se utiliza la función htmlreg del paquete “texreg” para mostrar los resultados de los tres modelos en una tabla HTML (al usar esta función en la consola de R remplace la función htmlreg por screenreg). En la llamada de la función htmlreg, se especifica una lista de modelos a mostrar como una lista (list(modelo1, modelo2, modelo3)) y un vector de nombres personalizados para los coeficientes de regresión (custom.coef.names = c(“Intercepto”,“Escolaridad”,“Edad”,“Sexo (ref. Hombre)"))
htmlreg(list(modelo1,modelo2,modelo3), custom.coef.names = c("Intercepto","Escolaridad","Edad","Sexo (ref. Hombre)"))
| Model 1 | Model 2 | Model 3 | |
|---|---|---|---|
| Intercepto | -261505.49*** | -594088.01*** | -674540.62*** |
| (10619.62) | (18905.38) | (18333.01) | |
| Escolaridad | 67850.97*** | 79569.00*** | 87210.88*** |
| (853.83) | (931.45) | (903.12) | |
| Edad | 6418.43*** | 6726.08*** | |
| (226.26) | (217.86) | ||
| Sexo (ref. Hombre) | -225226.51*** | -243306.54*** | |
| (7273.07) | (6956.87) | ||
| R2 | 0.06 | 0.08 | 0.10 |
| Adj. R2 | 0.06 | 0.08 | 0.10 |
| Num. obs. | 97033 | 97033 | 97033 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | |||
Se presenta a continuación la interpretación de los coeficientes del modelo 3.
-
Intercepto: El valor del intercepto (-674540.62) no siempre tiene una interpretación significativa, en tanto indica el valor predicho por el modelo para la variable dependiente cuando todas las variables independientes tienen valor 0.
-
Escolaridad: El coeficiente para la variable escolaridad (87210.88) indica que, manteniendo constantes las otras variables del modelo, por cada año adicional de escolaridad, se espera un aumento promedio en los ingresos autónomos de $87210.88.
-
Edad: El coeficiente para la variable edad (6726.08) indica que, manteniendo constantes las otras variables del modelo, por cada año adicional de edad, se espera un aumento promedio en los ingresos autónomos de $6726.08.
-
Sexo (ref. Hombre): El coeficiente para la variable sexo (ref. Hombre) (-243306.54) indica que, manteniendo constantes las otras variables del modelo, se espera que los ingresos autónomos promedio de una persona del sexo femenino sean en promedio $243306.54 menos que para una persona del sexo masculino en las mismas condiciones.
-
R2: El coeficiente de determinación (R2) indica que el modelo explica el 10% de la variabilidad de los ingresos autónomos.
-
Adj. R2: El coeficiente de determinación ajustado (Adj. R2) también indica que el modelo explica el 10% de la variabilidad de los ingresos autónomos, teniendo en cuenta el número de variables incluidas en el modelo.
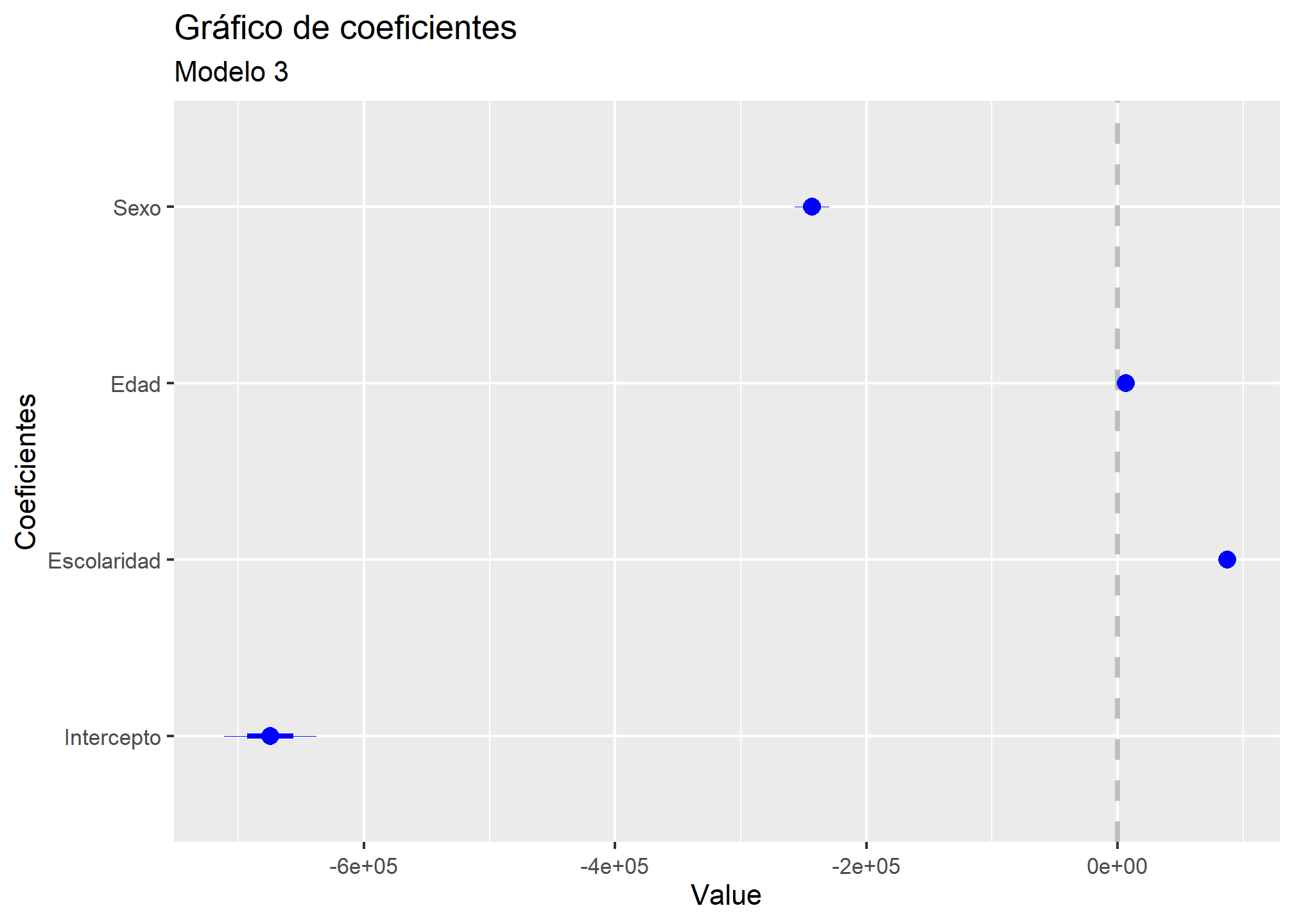
Finalmente, se utiliza la función coefplot del paquete “coefplot” para mostrar un gráfico de los coeficientes del modelo 3. Se especifica una escala de etiquetas para los ejes Y (scale_y_discrete) y se agregan títulos (labs) al gráfico.
coefplot(modelo3)+scale_y_discrete(labels=c("Intercepto","Escolaridad","Edad","Sexo","Sexo (ref. Hombre)"))+
labs(title = "Gráfico de coeficientes",subtitle = "Modelo 3")+ylab("Coeficientes")
Revisión de supuestos
A continuación se explica como comprobar los supuestos de los modelos de regresión lineal múltiple en R.
Casos influyentes
En esta sección se buscan observaciones influyentes utilizando la medida de distancia de Cook’s D. Se establece un punto de corte de Cook’s D utilizando la fórmula de 4/(n-k-1), donde n es el número de observaciones y k es el número de parámetros del modelo. Se utiliza la función augment_columns del paquete broom para crear una tabla con todas las variables del modelo junto con los residuos estandarizados y la distancia de Cook. Luego, se crea un gráfico de barras que muestra la distancia de Cook para cada observación, y se agrega una línea horizontal en el valor de corte y etiquetas para las observaciones que superan este valor. Finalmente, se filtran las observaciones influyentes utilizando el valor de corte y se crea un nuevo modelo de regresión sin ellas. Se utiliza la función htmlreg del paquete htmlreg para mostrar la tabla comparativa de los modelos original y el nuevo sin las observaciones influyentes.
n<- nobs(modelo3) #n de observaciones
k<- length(coef(modelo3)) # n de parametros
dcook<- 4/(n-k-1) #punt de corte
final <- broom::augment_columns(modelo3,data = base)
final$id <- as.numeric(row.names(final))
# identify obs with Cook's D above cutoff
ggplot(final, aes(id, .cooksd))+
geom_bar(stat="identity", position="identity")+
xlab("Obs. Number")+ylab("Cook's distance")+
geom_hline(yintercept=dcook)+
geom_text(aes(label=ifelse((.cooksd>dcook),id,"")),
vjust=-0.2, hjust=0.5)
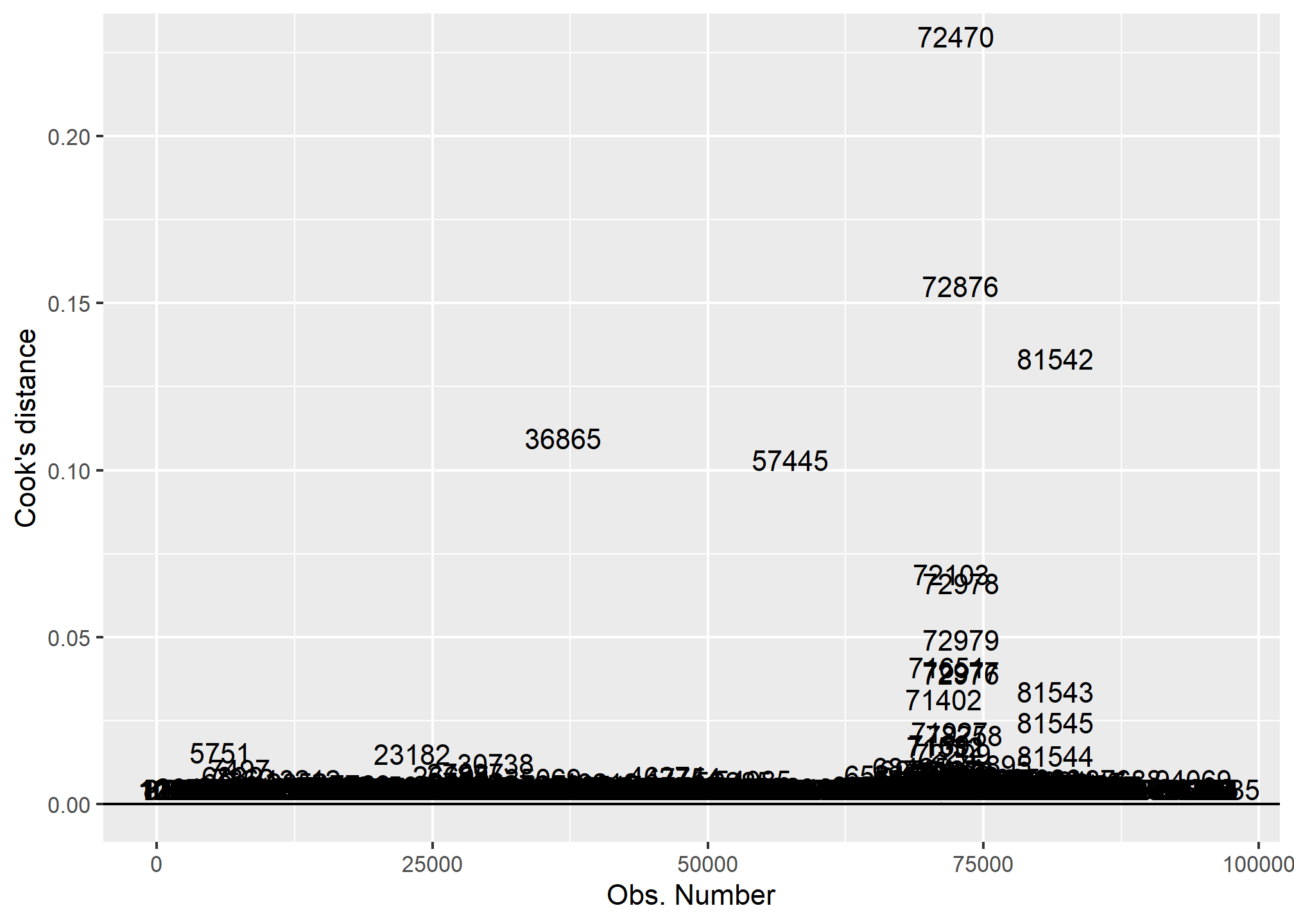
ident<- final %>% filter(.cooksd>dcook)
base2<- final %>% filter(!(id %in% ident$id))
modelo4<-lm(yautcor~ esc+ edad+ as_factor(sexo),data = base2,weights = expr)
htmlreg(list(modelo3,modelo4), custom.coef.names = c("Intercepto","Escolaridad","Edad","Sexo (ref. Hombre)"))
| Model 1 | Model 2 | |
|---|---|---|
| Intercepto | -674540.62*** | -333646.62*** |
| (18333.01) | (6927.29) | |
| Escolaridad | 87210.88*** | 58232.06*** |
| (903.12) | (348.59) | |
| Edad | 6726.08*** | 3981.04*** |
| (217.86) | (81.17) | |
| Sexo (ref. Hombre) | -243306.54*** | -156878.56*** |
| (6956.87) | (2572.57) | |
| R2 | 0.10 | 0.25 |
| Adj. R2 | 0.10 | 0.25 |
| Num. obs. | 97033 | 94655 |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
Linealidad
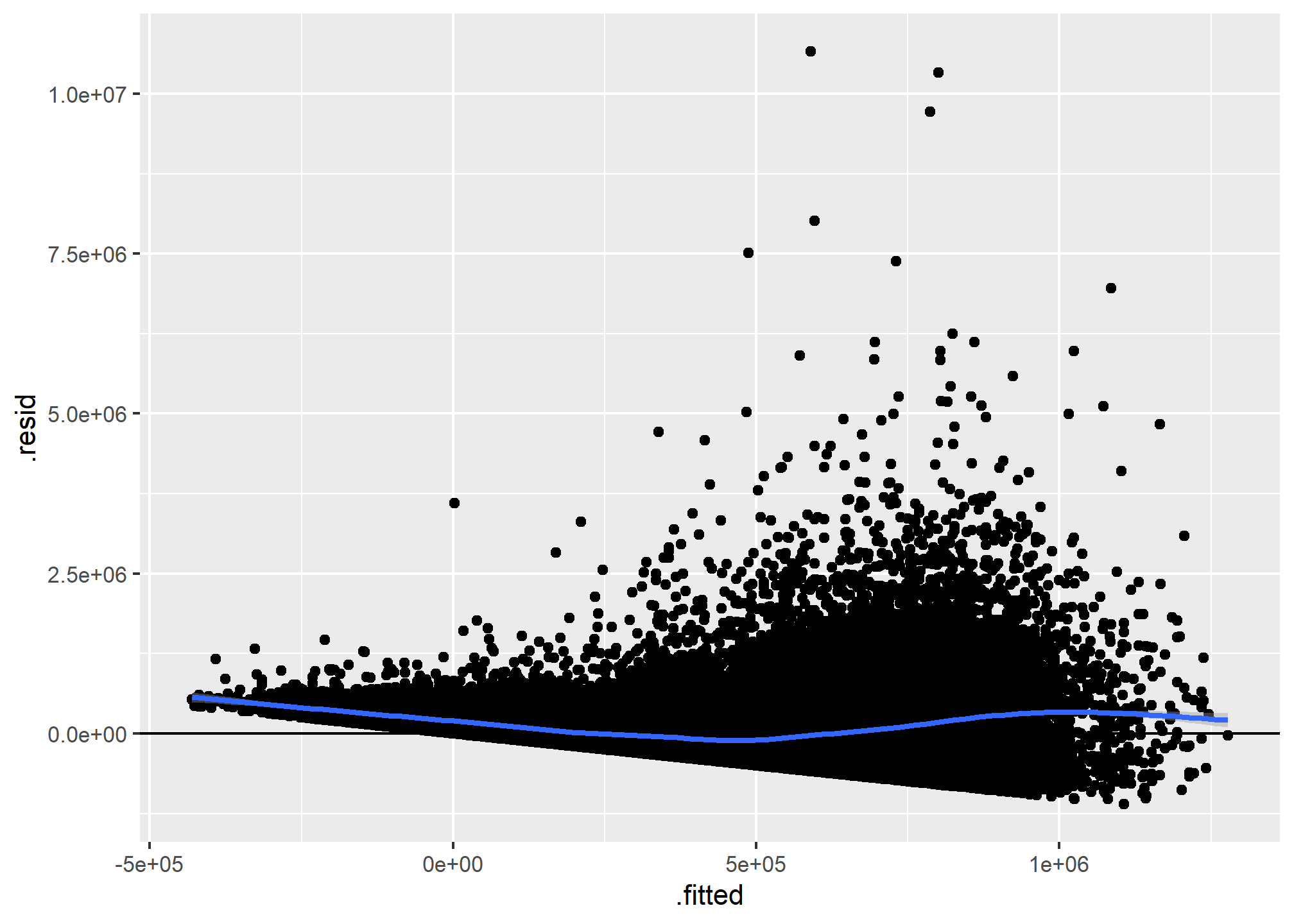
En esta sección se verifica la suposición de linealidad mediante un gráfico de dispersión de los valores ajustados contra los residuos. Se utiliza la función ggplot del paquete ggplot2 para crear el gráfico, y se agregan una línea horizontal en y=0 y una curva suavizada de los residuos estandarizados.
ggplot(modelo4, aes(.fitted, .resid)) +
geom_point() +
geom_hline(yintercept = 0) +
geom_smooth(se = TRUE)
## `geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'
Homogeneidad de varianza
En esta sección se verifica la suposición de homogeneidad de varianza mediante el test de Breusch-Pagan. Se utiliza la función ncvTest del paquete car para realizar el test y se muestra el resultado. Luego, se utiliza la función coeftest del paquete lmtest para crear una versión robusta del modelo utilizando la matriz de covarianza de Huber-White y se muestra una tabla comparativa de los coeficientes del modelo original y el modelo robusto utilizando la función htmlreg.
car::ncvTest(modelo4)
Non-constant Variance Score Test Variance formula: ~ fitted.values Chisquare = 28265.61, Df = 1, p = < 2.22e-16
model_robust<- coeftest(modelo4, vcov=vcovHC)
htmlreg(list(modelo4,model_robust), custom.coef.names = c("Intercepto","Escolaridad","Edad","Sexo (ref. Hombre)"))
| Model 1 | Model 2 | |
|---|---|---|
| Intercepto | -333646.62*** | -333646.62*** |
| (6927.29) | (7733.36) | |
| Escolaridad | 58232.06*** | 58232.06*** |
| (348.59) | (457.22) | |
| Edad | 3981.04*** | 3981.04*** |
| (81.17) | (86.29) | |
| Sexo (ref. Hombre) | -156878.56*** | -156878.56*** |
| (2572.57) | (2973.76) | |
| R2 | 0.25 | |
| Adj. R2 | 0.25 | |
| Num. obs. | 94655 | |
| ***p < 0.001; **p < 0.01; *p < 0.05 | ||
En esta sección se verifica la suposición de multicolinealidad mediante el cálculo del factor de inflación de la varianza (VIF) para cada variable independiente del modelo.
VIF (variance inflation factor) es una medida de la multicolinealidad en un modelo de regresión. Mide el grado en que los predictores están correlacionados entre sí. Un valor VIF de 1 indica que no hay multicolinealidad, mientras que un valor VIF mayor que 1 indica que los predictores están correlacionados y se inflan los errores estándar de los coeficientes. Los valores comúnmente aceptados para el VIF son menores de 2.5 o 5. Valores mayores a estos pueden indicar problemas de multicolinealidad en el modelo.
car::vif(modelo4) #Se espera que no existan valores mayores a 2.5
## esc edad as_factor(sexo)
## 1.232273 1.230670 1.003348
Normalidad de los residuos
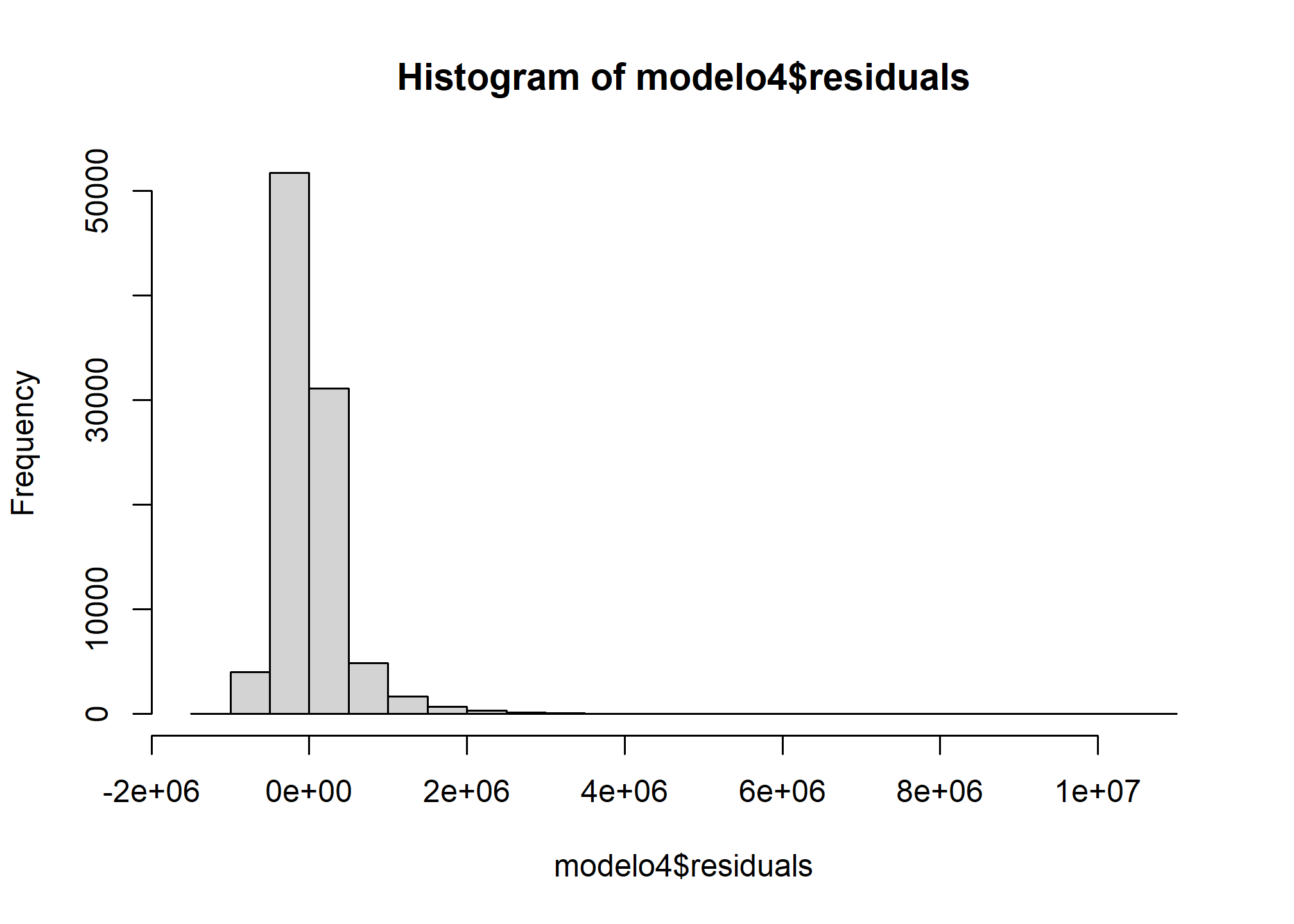
En esta sección se verifica la suposición de normalidad de los residuos mediante un histograma de los mismos. Se utiliza la función hist de R para crear el histograma.
#Normalidad de los residuos
hist(modelo4$residuals)