2. Uso de bases de datos en R, estadística descriptiva y visualización
0. Objetivo del práctico
El objetivo de este práctico es aprender el uso de funciones y paquetes en R, con el fin de cargar bases de datos, realizar análisis descriptivos y representaciones gráficas básicas.
Para esto haremos uso de la encuesta CASEN (2020), la mayor encuesta de hogares realizada en Chile, a cargo del Ministerio de Desarrollo Social, de carácter transversal y multipropósito, es el principal instrumento de medición socioeconómica para el diseño y evaluación de la política social. Permite conocer periódicamente la situación socioeconómica de los hogares y de la población que reside en viviendas particulares, a través de preguntas referidas a composición familiar, educación, salud, vivienda, trabajo e ingresos, entre otros aspectos.
1. Paquetes y funciones en R
Cuando descargamos e instalamos R este contiene una cantidad limitada de funciones disponibles, las cuales podemos ampliar mediante la descarga de distintos paquetes creados por la comunidad de usuarios, los cuales nos permitirán, mediante nuevas funciones, ampliar las capacidades del programa, en términos de gestión de bases de datos, análisis estadísticos, visualización de datos, y muchas otras funciones.
En la siguiente práctica queremos usar la base de datos de CASEN, la cuál está disponible en formato .sav (SPPS) y .dta (STATA), formatos que no son soportados por la versión base de R. Para poder cargar la base de datos como un objeto en R usaremos el paquete haven, el cual incluye funciones para cargar datos a R en diversos formatos.
# install.packages("haven")
#este comando nos permite instalar paquetes alojados en CRAN
library(haven) #Este comando nos permite ejecutar el paquete
Una vez cargado el paquete debemos descargar la base de datos y ubicarla en nuestro computador para poder cargarla con la función read_spss(). Para esto debemos establecer un directorio de trabajo, es decir, la carpeta raíz a partir de la cual R buscará los archivos que queremos cargar en nuestro espacio de trabajo, y donde guardará los output de nuestros análisis.
#La sigueitne función nos permite dentificar el irectorio de trabajo actual
getwd()
#debemos fijar un directorio de trabajo a la carpeta en que tendremos nuestros archivos, por ejemplo:
setwd("C:/Users/Gabriel/Desktop/Directorio R")
# Nota: Debe usarse el simbolo "/" y NO "\"
Una vez que hemos fijado nuestro directorio de trabajo podemos cargar nuestra base de datos y asignarla como objeto, para que se guarde en el ambiente y poder usarla posteriormente en nuestros análisis.
casen2020<-read_spss("Casen_en_Pandemia_2020_revisada202209.sav")
Una forma alternativa de realizar este proceso es descargar directamente los datos mediante el uso de código. Esto ofrece la ventaja de que nos permite ejecutar el código en otros computadores y obtener automáticamente los datos. Un posible problema de esta forma de cargar los datos es que cuando usamos archivos de gran tamaño puede ser muy poco eficiente.
temp <- tempfile() #Creamos un archivo temporal
download.file("http://observatorio.ministeriodesarrollosocial.gob.cl/storage/docs/casen/2020/Casen_en_Pandemia_2020_revisada202209.sav.zip",temp) #descargamos los datos
casen <- haven::read_sav(unz(temp, "Casen_en_Pandemia_2020_revisada202209.sav")) #cargamos los datos
unlink(temp); remove(temp) #eliminamos el archivo temporal
2. Estadística Descriptiva
Para obtener estadísticos descriptivos en R, tales como la media, la mediana o la desviación estándar debemos usar las funciones incluidas para esto en R. Para esto utilizaremos la variable “ytotcorh” que corresponde al ingresos total corregido de los hogares.
#media
mean(casen$ytotcorh) #nos devuelve NA dado que hay casos perdidos
## [1] NA
mean(casen$ytotcorh,na.rm=T) #debemos agregar un argumento indicando que no considere los casos perdidos
## [1] 1231376
#mediana
median(casen$ytotcorh,na.rm=T)
## [1] 859083
#Varianza y desviación estandar
var(casen$ytotcorh,na.rm=T)
## [1] 2.510218e+12
sd(casen$ytotcorh,na.rm=T)
## [1] 1584367
#Cuantiles
quantile(casen$ytotcorh, probs = c(0.25,0.50,0.75,0.9),na.rm = TRUE) #percetniles
## 25% 50% 75% 90%
## 557961 859083 1394787 2346667
#minimo
min(casen$ytotcorh,na.rm = TRUE)
## [1] 0
#máximo
max(casen$ytotcorh,na.rm = TRUE)
## [1] 225500000
#summary nos entrega un resumen de la variable
summary(casen$ytotcorh)
## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0 557961 859083 1231376 1394787 225500000 98
Del mismo modo podemos obtener tablas de frecuencia absoluta y relativa.
table(casen$sexo)
##
## 1 2
## 86096 99341
#Para usar las etiquetas de las variables cargadas en e formato spss podemos usar el comando as_factor()
table(as_factor(casen$sexo))
##
## Hombre Mujer
## 86096 99341
#prop.table nos da una tabla de proporciones a partir de una tabla
prop.table(table(as_factor(casen$sexo)))
##
## Hombre Mujer
## 0.4642871 0.5357129
#El comando table también nos permite obtener tablas cruzadas
table(as_factor(casen$sexo),as_factor(casen$pobreza))
##
## Pobres extremos Pobres no extremos No pobres
## Hombre 3805 5792 76494
## Mujer 4630 7070 87548
#si añadimos el argumento 1 nos dará porcentajes fila y 2 nos dará porcentajes columna
prop.table(table(as_factor(casen$sexo),as_factor(casen$pobreza)),1)
##
## Pobres extremos Pobres no extremos No pobres
## Hombre 0.04419742 0.06727765 0.88852493
## Mujer 0.04665081 0.07123569 0.88211349
3. Gestión de datos
A continuación, revisaremos como realizar algunas cuestiones básicas de gestión de datos en R. Un aspecto relevante a tener un cuenta es que R, dado su carácter abierto, suele existir más de una solución para realizar cada tipo de análisis. En el caso de la gestión de datos, esto puede hacer a partir de las funciones base de R o a partir de funciones del paquete dplyr, el cual forma parte de tidyverse, el cuál consiste en un conjunto de paquetes para ciencia de datos desarrollados con una filosofía, gramática y estructura de datos en común.
Para seleccionar solo las variables que necesitamos de una base de datos podemos utilizar R base a partir de los nombres o índices de las variables (su posición dentro de la base de datos). En dplyr podemos usar la función select.
#Seleccionar variables
#R base
casen1<-casen[,c("folio","o","zona","sexo","edad")]
casen2<-casen[,1:2]
library(dplyr)
casen3<-select(casen, folio,o,pobreza) #dplyr
Para filtrar casos de acuerdo a ciertas características podemos usar condiciones lógicas a partir de r base utilizando la estructura base[filas,columnas] para hacer un subset de la base de datos, o utilizar la función filter de dplyr.
#Filtrar casos
#R base
casen1a<-casen1[casen1$zona==1&casen1$sexo==1,] #seleccionar casos urbanos
#dplyr
casen1b<-filter(casen1, sexo==1) #dplyr
casen1c<-casen1 %>% select(sexo,zona)%>% filter(sexo==2) #dejar solo la variable sexo y zona y luego solo a las mujeres
Para crear nuevas variables podemos utilizar R base a través de condiciones lógicas, o la función recode del paquete car. Podemos ver que ambos procedimientos producen el mismo resultado, pero en general la sintaxis de recode resulta más simple y legible.
#Recodificar/crear varibles
#Rbase
casen1$edadt[casen1$edad<16]=1
casen1$edadt[casen1$edad>=16&casen1$edad<60]=2
casen1$edadt[casen1$edad>=60]=3
#car
#install.packages("car")
library(car)
casen1$edadt2 <- car::recode(casen1$edad, "0:15 = 1; 16:59=2; 60:120=3")
table(casen1$edadt==casen1$edadt2)
##
## TRUE
## 185437
4. Visualización básica de datos
R entrega una serie de herramientas para la visualización de datos. En este caso revisaremos brevemente las herramientas básicas de visualización de datos que trae R base.
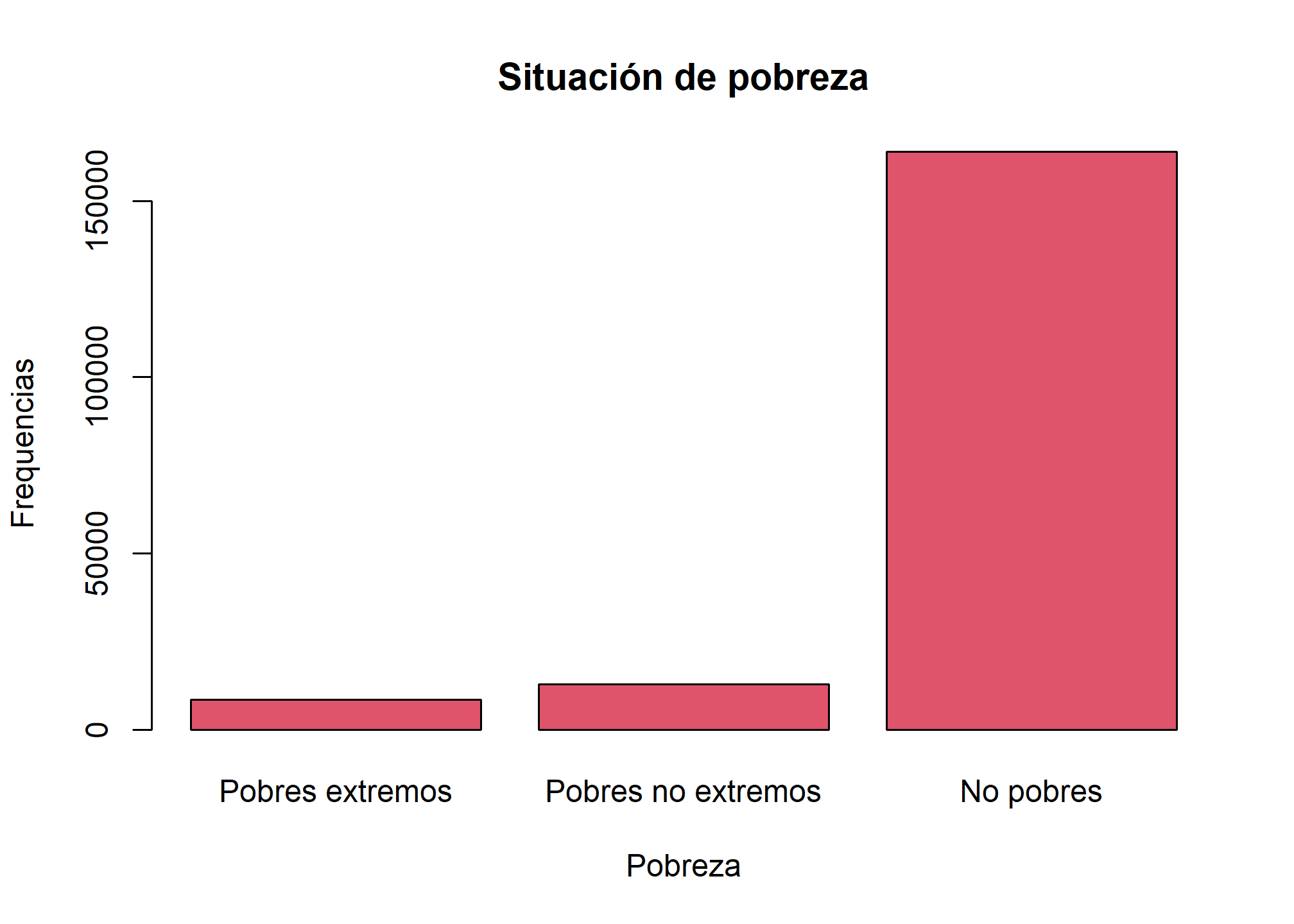
#Gráfico de barras
plot(as_factor(casen$pobreza), main="Situación de pobreza", xlab="Pobreza",ylab="Frequencias",
col=2)
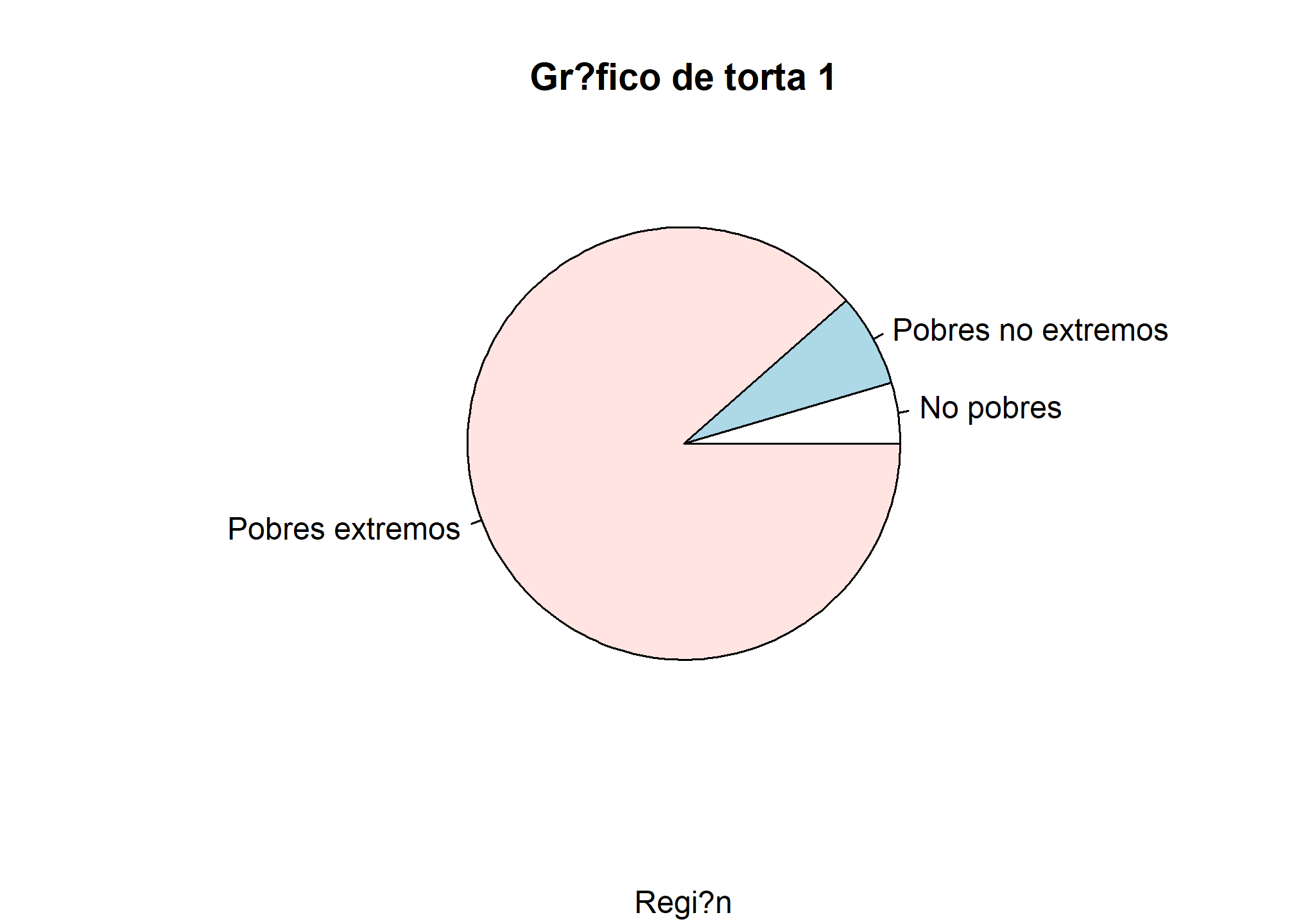
#Gráfico de torta
valores<-as.numeric(prop.table(table(casen$pobreza)))
pie(valores, labels = c("No pobres","Pobres no extremos","Pobres extremos"),
main = "Gr?fico de torta 1",
sub = "Regi?n")
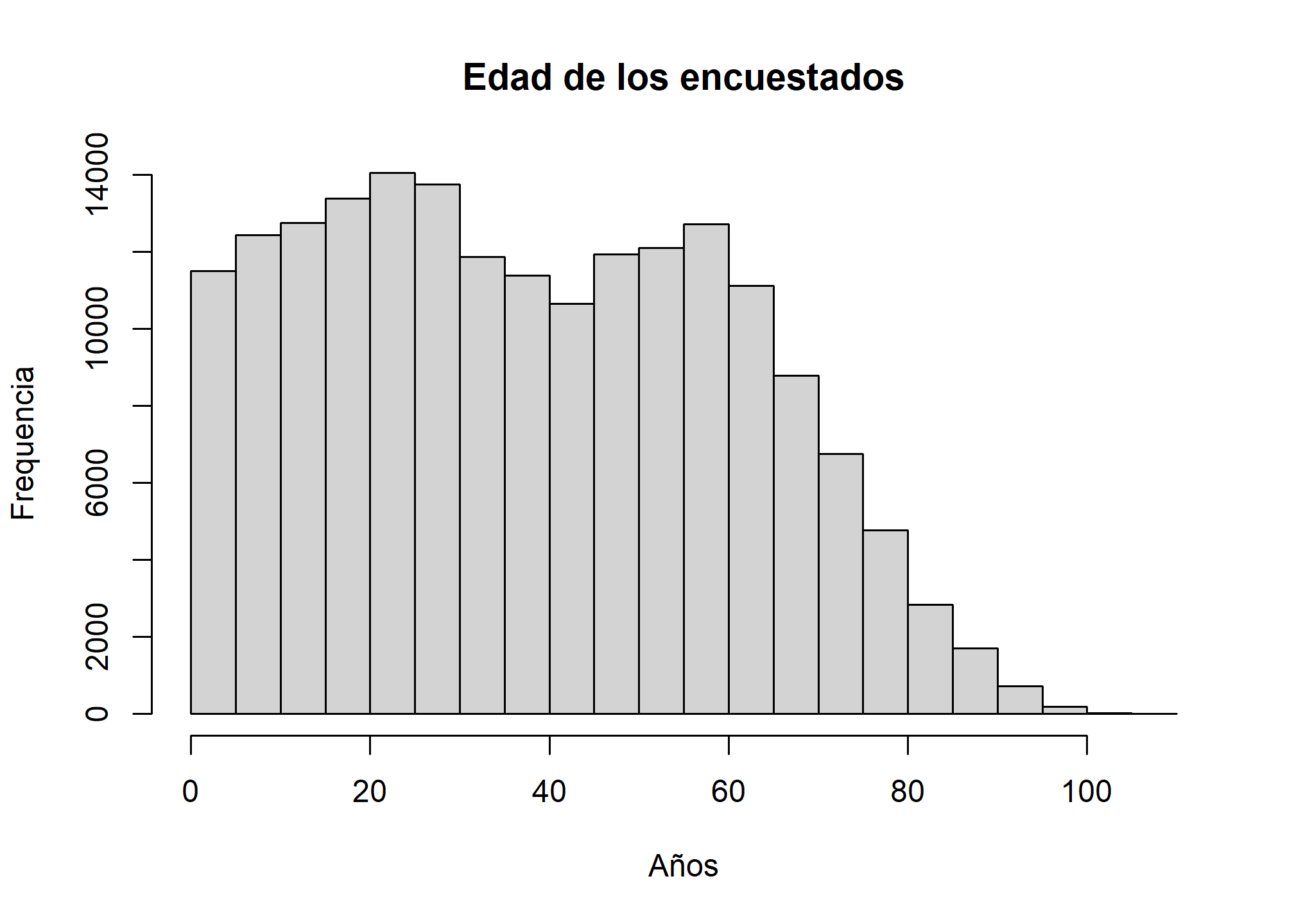
#Histogramas
hist(casen$edad,main="Edad de los encuestados", xlab="Años",ylab="Frequencia")
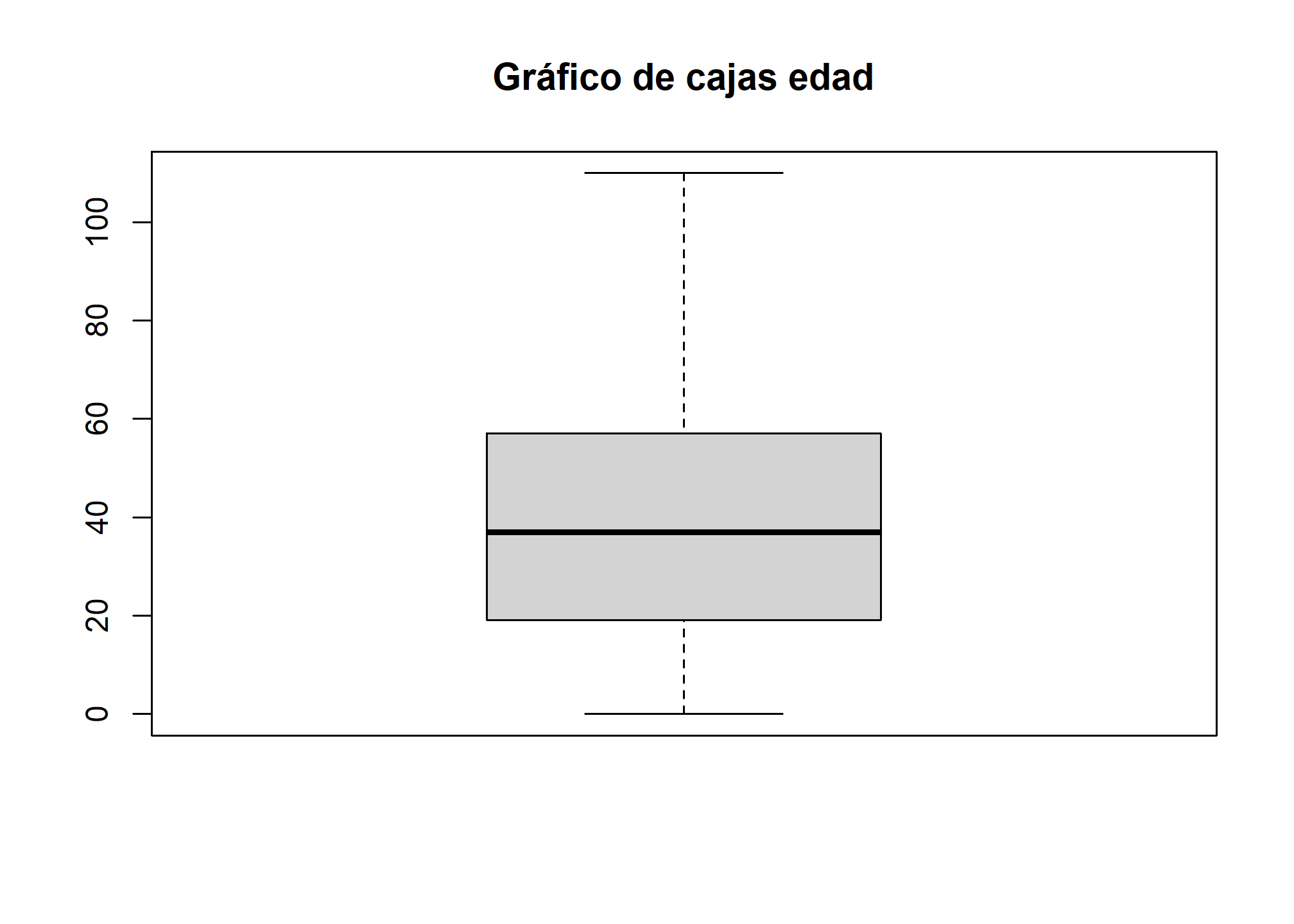
#boxplot
boxplot(casen$edad, main = "Gráfico de cajas edad",
outline = TRUE)
Una mejor herramienta para la visualización de datos en R es el paquete ggplot2. Para una introducción básica a este pueden revisar la siguiente Introducción al uso del paquete ggplot2. Para una revisión más profunda pueden revisar los capítulos 3 y 28 del libro R para ciencia de datos